Chapitre3 Preparation des données SOL
3.1 IMPORTATION DES DONNEES SOL SOUS R
Ce fichier présente pas à pas la préparation des données Sols sous R. Chaque étape est détaillée et commentée. Il est possible de faire des codes plus optimisés mais étant moins pédagogiques, nous avons choisis de vous présenter des codes assez détaillés pour une meilleure compréhension des étapes. Des options vous seront également proposées si vous souhaitez aller plus loin.
3.1.1 Les données Sol
Les données sols sont issues des fichiers d’export en format CSV de l’interface DoneSol-web https://dw4.gissol.fr/login. Sur le menu d’accueil de l’interface DoneSol-web, il suffit de choisir “Exporter” et de sélectionner la ou les étude(s) à exporter pour obtenir chaque table de DoneSol en format CSV contenant les données des études choisies. Avant d’exporter, il faut choisir le type de séparateur pour l’export en CSV : “,” ou “;”. Le mieux est de choisir “;”.
Pour en savoir plus sur l’export des données depuis l’interface DoneSol-web, vous pouvez consulter la vidéo “17- Les outils d’export des données” sur https://www.gissol.fr/outils/formations-en-ligne-videos-sur-la-saisie-des-donnees-dans-donesol-web-3638.
Pour en savoir plus sur les tables de DoneSol, vous pouvez consulter le dictionnaire de données de DoneSol téléchargeable à partir du menu d’accueil de l’interface DoneSol-web.
Nous importons ici sous R les tables des données ponctuelles de DoneSols. Les fichiers doivent avoir les mêmes noms que dans le dictionnaire DoneSol. L’ensemble des fichiers .csv doivent être stockés dans un même dossier que l’on nommera “donesol”. Pour cette importation, nous utilisons le package dplyr :
ⓘ NOTE
Un package est un ensemble de fonctions, de données et de documentation développé par la communauté R pour répondre à des besoins spécifiques et qui améliorent ou étendent les fonctionnalités de base de R.
Par la suite, il faut bien préciser le type de séparation des champs tel que nous l’avons choisi lors de l’export sous DoneSol-web.
Les données sont donc en format DoneSol et sont réparties dans différentes tables reliées entre elles. Les données utilisées sont des données ponctuelles issues de la description de profils et de sondages sur le terrain. Le schéma suivant présente la structure DoneSol pour les données ponctuelles :
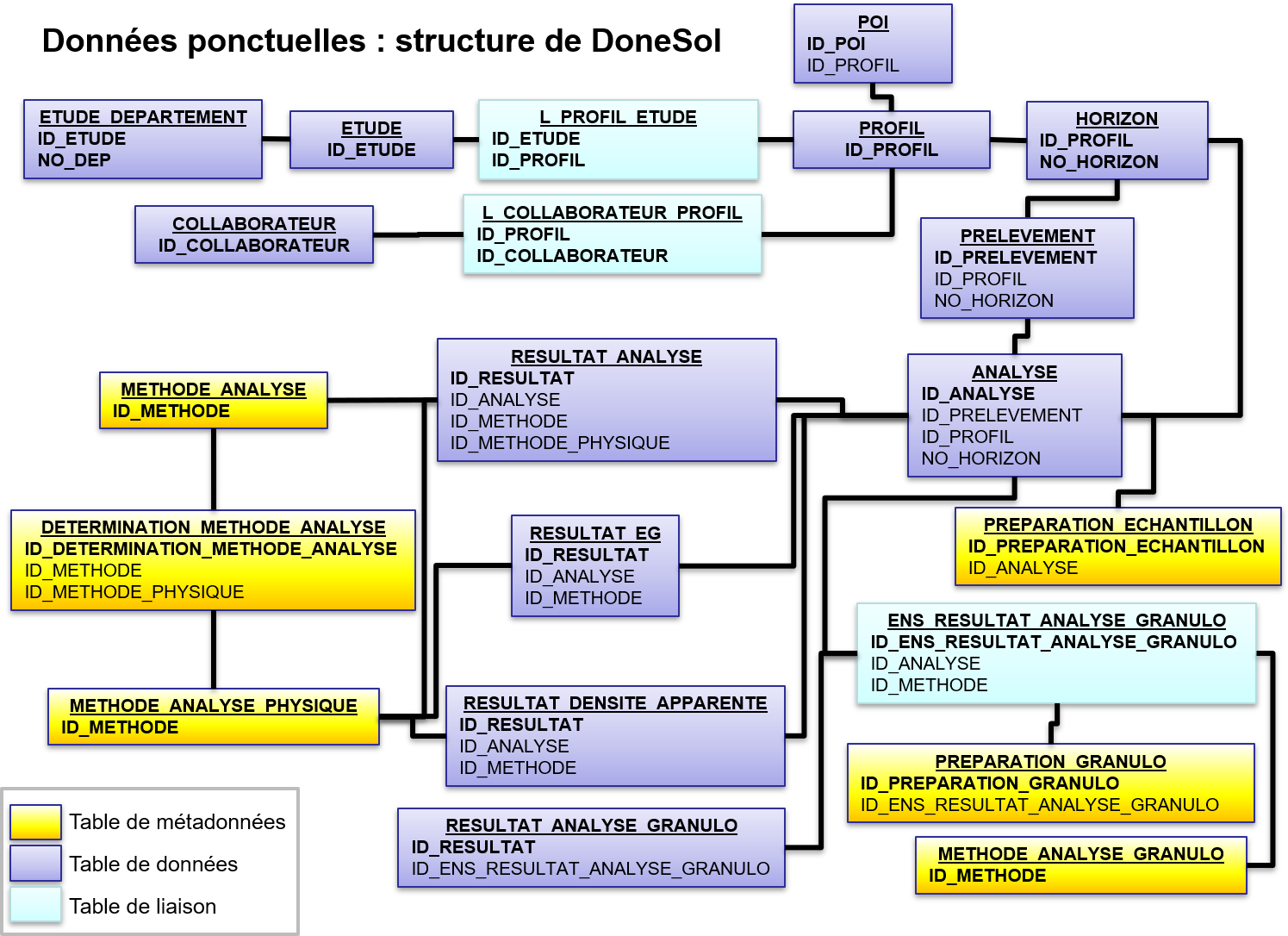
Pour relier deux tables, nous utilisons les champs identiques dans chacune des tables. Par exemple, pour relier la table POI contenant les XY des points et la table PROFIL, nous utilisons le champ ID_PROFIL. Il est donc important de conserver ces champs tout au long de notre travail.
3.1.2 Importation de la table PROFIL
La table PROFIL contient la description synthétique du profil de sol (fosse, sondage à la tarrière…). La table PROFIL décrit la localisation géographique du profil, son environnement, sa situation géomorphologique, son organisation géologique, les différentes origines de sa différenciation en horizons, ses caractéristiques hydriques et sa classification.
Pour importer la table PROFIL, nous devons spécifier le chemin du fichier .csv correspondant. Pour cela, le plus simple est d’avoir l’ensemble de vos fichiers dans le même dossier que votre projet R.
De même, il est important de conserver les champs constituant les clefs des tables. Cette information est disponible dans le dictionnaire de données DoneSol et peut concerner 1 ou plusieurs champs selon les tables. Par exemple, pour la table PROFIL il s’agit du champ ID_PROFIL ; pour la table HORIZON il s’agit des champs ID_PROFIL et NO_HORIZON. Ces champs vous permettrons de faire le lien entre les tables.
profil <- read.csv2('donnees/jour1/donesol/profil.csv', sep=";")Nous sélectionnons les champs que nous souhaitons garder pour la suite. Vous pouvez modifier ce code pour sélectionner les champs de la table PROFIL qui vous intéressent. Il est conseillé de conserver le nom des champs identique à celui du dictionnaire de données pour éviter des confusion par la suite. Il est important aussi de ne pas oublier un champ qui nous sera utile par la suite. Cette étape est importante et devra s’appuyer sur le dictionnaire de données DoneSol.
profil <- data.frame("id_profil"=profil$id_profil, # identifiant du profil
"altitude"=profil$altitude, # altitude du profil
"date_p"=profil$date_p, # date de description du profil
"occup_codee"=profil$occup_codee, # occupation du sol
"drai_nat_p"=profil$drai_nat_p, # drainage naturel
"arret"=profil$arret, # cause d'arrêt de la description
"prof_arret"=profil$prof_arret, # profondeur maximale observée
"rp_95_ger"=profil$rp_95_ger, # GER selon le RP 95
"rp_2008_ger"=profil$rp_2008_ger, # GER selon le RP 2008
"cpcs_nom"=profil$cpcs_nom) # nom du sol dans la classification CPCS
str(profil) # visualiser la liste des champs de la table PROFIL avec les valeurs des premiers enregistrements## 'data.frame': 2894 obs. of 10 variables:
## $ id_profil : int 110185 132400 96907 84414 131978 90327 137960 110218 90246 96908 ...
## $ altitude : chr "" "" "105.0" "151.0" ...
## $ date_p : chr "01/10/1975" "15/04/1990" "14/08/1986" "17/09/1991" ...
## $ occup_codee: int 600 500 500 500 500 130 100 600 500 5010 ...
## $ drai_nat_p : int NA NA NA NA 7 NA 6 NA NA NA ...
## $ arret : int 1 2 1 1 1 1 1 1 1 1 ...
## $ prof_arret : int NA NA NA NA NA NA NA NA NA NA ...
## $ rp_95_ger : int NA NA 16 NA NA NA NA NA NA 16 ...
## $ rp_2008_ger: logi NA NA NA NA NA NA ...
## $ cpcs_nom : int 7114 7110 7110 2430 7114 7110 7114 7126 7114 7110 ...ⓘ NOTE
Vous pouvez aussi obtenir le même résultat avec un code plus simple en indiquant le numéro de la colonne des variables que vous souhaitez conserver. Bien sûr, cette sélection doit être faite sur le fichier PROFIL brut importé au départ.
Le code suivant donne le numéro de la colonne du champ ID_PROFIL dans la table PROFIL :
which(colnames(profil) == “id_profil”)
Pour visualiser les numéros de toutes les colonnes de la table en une seule fois : names(PROFIL)
Une fois les numéros de colonnes identifiés, on peut les sélectionner avec :
profil <- profil[,c(1,5,6,33,82,86,87,92,96,91)]
3.1.2.1 Option 1 : Simplification de l’occupation du sol
Si nous souhaitons simplifier les occurences de l’occupation du sol, nous pouvons les regrouper en 8 classes : Forêts, Prairies permanentes, Cultures, Vergers, Maraîchage, Autres, Vignes, Environnements naturels. Nous y rajoutons une 9ème classe pour les données manquantes que nous nommerons ND (comme No Data - Pas de données).
Les classes souhaitées sont :
1- Forêts
2- Prairies permanentes
3- Cultures
4- Vergers
5- Maraîchage
6- Autres
7- Vignes
8- Environnements naturels
9- ND
# création et recodage du champ landuse contenant l'occupation du sol
profil <- profil %>%
mutate(
occup_codee = as.numeric(occup_codee),
landuse = case_when(
# Classe 1
between(occup_codee, 2000, 4200) ~ 1,
# Classe 2
between(occup_codee, 600, 603) ~ 2,
# Classe 3 (plusieurs intervalles)
between(occup_codee, 100, 509) ~ 3,
between(occup_codee, 700, 905) ~ 3,
between(occup_codee, 1400, 1600) ~ 3,
between(occup_codee, 6000, 6080) ~ 3,
# Classe 4
between(occup_codee, 1100, 1164) ~ 4,
# Classe 5
between(occup_codee, 1000, 1050) ~ 5,
# Classe 6
between(occup_codee, 1200, 1250) ~ 6,
between(occup_codee, 5200, 5250) ~ 6,
# Classe 7
between(occup_codee, 1300, 1303) ~ 7,
# Classe 8
between(occup_codee, 5000, 5151) ~ 8,
between(occup_codee, 7000, 13100) ~ 8,
# Sinon NA
TRUE ~ NA_real_
),
landuse = factor(landuse)
)
head(profil$landuse) # permet de connaître les classes présentes dans le jeu de données## [1] 2 3 3 3 3 3
## Levels: 1 2 3 4 5 8
summary(profil$landuse) # et de connaitre le nombre de profils pour chaque occupation des sols## 1 2 3 4 5 8 NA's
## 8 332 2166 14 14 84 276
# La classe "NA's" correspond à des profils sans occupation du sol.
# Ces informations sont ensuite utilisée pour affecter les labels des classes
profil$landuse<-factor(profil$landuse,
labels=c("Forets",
"Prairies_permanentes",
"Cultures",
"Vergers",
"Maraichage",
"Environnements_naturels")
)
# Nous mettons les données manquantes (NA's) dans la classe ND.
profil$landuse<-factor(ifelse(is.na(profil$landuse),
"ND",
paste(profil$landuse)),
levels = c(levels(profil$landuse),
"ND"))
summary(profil$landuse) # Affiche le nombre de profils par occupation du sol## Forets Prairies_permanentes Cultures
## 8 332 2166
## Vergers Maraichage Environnements_naturels
## 14 14 84
## ND
## 276
# Présenter l'occupation des sols sous forme de graphique
ggplot(profil, aes(x=factor(landuse)))+
geom_bar(stat="count", width=0.7,fill= "darkolivegreen4")+
ylab("Nombre de profils")+
xlab("Occupation du sol") +
scale_x_discrete(labels = c("Forets" = "Forêts",
"Prairies_permanentes" = "Prairies\npermanentes",
"Cultures" = "Cultures",
"Vergers" = "Vergers",
"Maraichage"="Maraîchage",
"Environnements_naturels"="Environnements\nnaturels",
"ND"="Non connue")) +
# ajout du nombre de profils par classe
geom_text(aes(label = after_stat(count)),
stat = "count",
vjust=0) +
theme_minimal()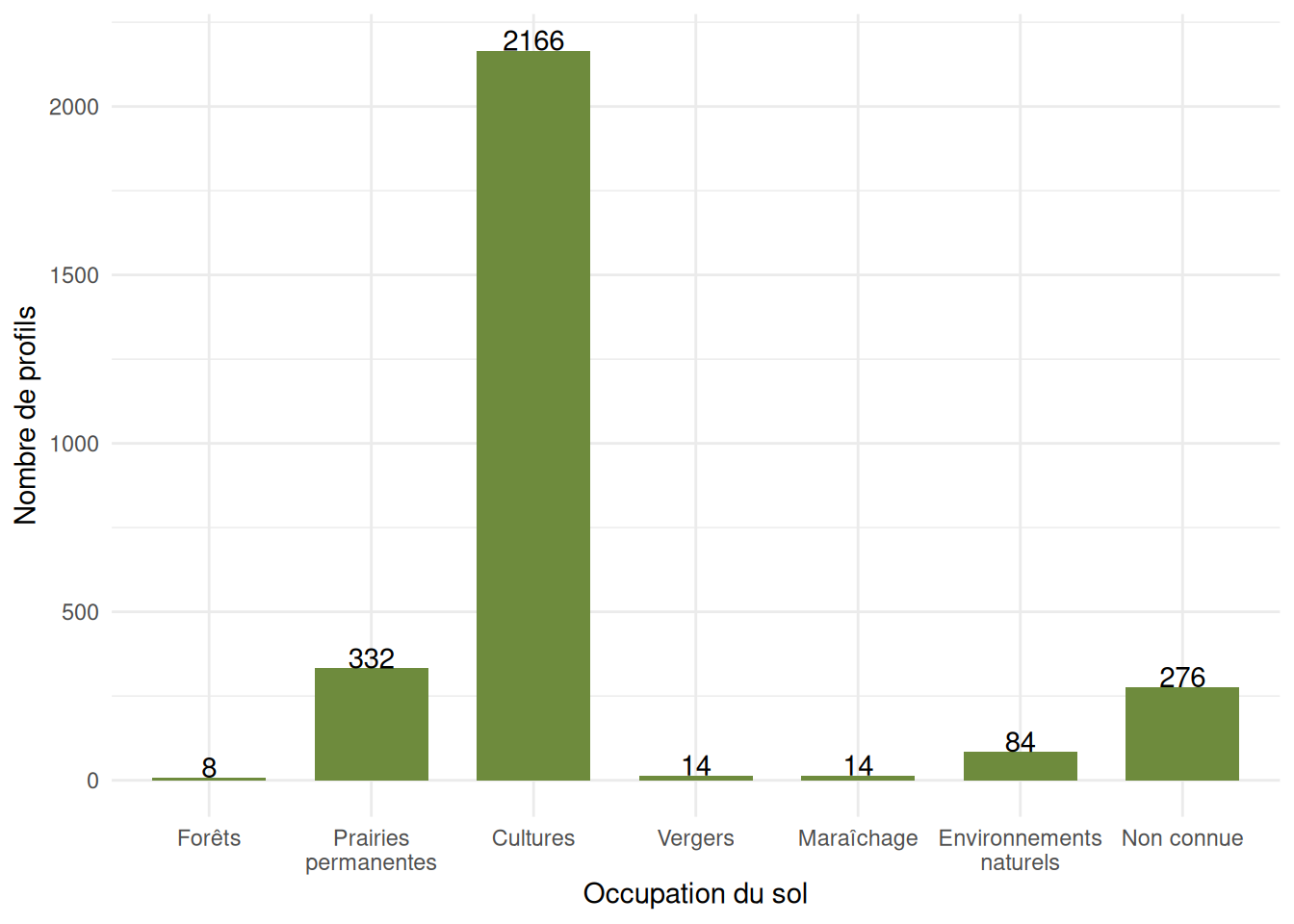
3.1.2.2 Option 2 : Simplification des types de sols (GER)
Dans DoneSol, il y a 3 classifications couramment utilisées en France : CPCS, RP95 et RP2008. Le choix de la classification dépend de la date de description. Les données les plus ancienens sont décrites en CPCS et les plus récentes en RP2008. Nous souhaitons ici utiliser ces trois classifications pour créer un champ contenant le type de sol (GER = Grands Ensembles de Références). Nous allons partir de la classification la plus récente (RP2008) puis nous complétons les valeurs manquantes avec le RP95 puis avec la CPCS recodée en RP.
Dans DoneSol, le RP2008 et le RP95 sont des champs codés. Nous allons commencer par remplacer le code par le nom du GER. Nous allons utiliser le fichier “dico_profil_horizon.xlsx” contenant la correspondance entre les code et leur signification.
# chargement du fichier contenant la signification des codes
library(readxl)
dico <- read_xlsx('donnees/jour1/dico_profil_horizon.xlsx')
dico<-data.frame(dico)
# sous-ensembles du dico par classification de sol puis mise en facteurs des codes pour chaque classification
dico_ger2008<-subset(dico, variable=="rp_2008_ger")
dico_ger2008<-data.frame("rp_2008_ger"=dico_ger2008$code, "label_RP2008"=dico_ger2008$label)
dico_ger2008$rp_2008_ger<-as.factor(dico_ger2008$rp_2008_ger)
dico_ger95<-subset(dico, variable=="rp_95_ger")
dico_ger95<-data.frame("rp_95_ger"=dico_ger95$code, "label_RP95"=dico_ger95$label)
dico_ger95$rp_95_ger<-as.factor(dico_ger95$rp_95_ger)
dico_cpcs<-subset(dico, variable=="cpcs_nom")
dico_cpcs<-data.frame("cpcs_nom"=dico_cpcs$code, "label_cpcs"=dico_cpcs$label)
dico_cpcs$cpcs_nom<-as.integer(dico_cpcs$cpcs_nom)
# Mise en facteur des champs RP de la table PROFIL
profil$rp_2008_ger<-as.factor(profil$rp_2008_ger)
profil$rp_95_ger<-as.factor(profil$rp_95_ger)
# Nous rajoutons la signification des codes (labels) pour les 3 classifications dans la table PROFIL.
# Pour cela nous utilisons la jointure à gauche (voir note sur les jointures).
library(dplyr)
a<-dplyr::left_join(profil, dico_ger2008, by="rp_2008_ger")
b<-dplyr::left_join(a, dico_ger95, by="rp_95_ger")
profil<-dplyr::left_join(b, dico_cpcs, by="cpcs_nom")
# Nous supprimons les fichiers a et b devenus inutiles
rm(a)
rm(b)ⓘ NOTE SUR LES JOINTURES
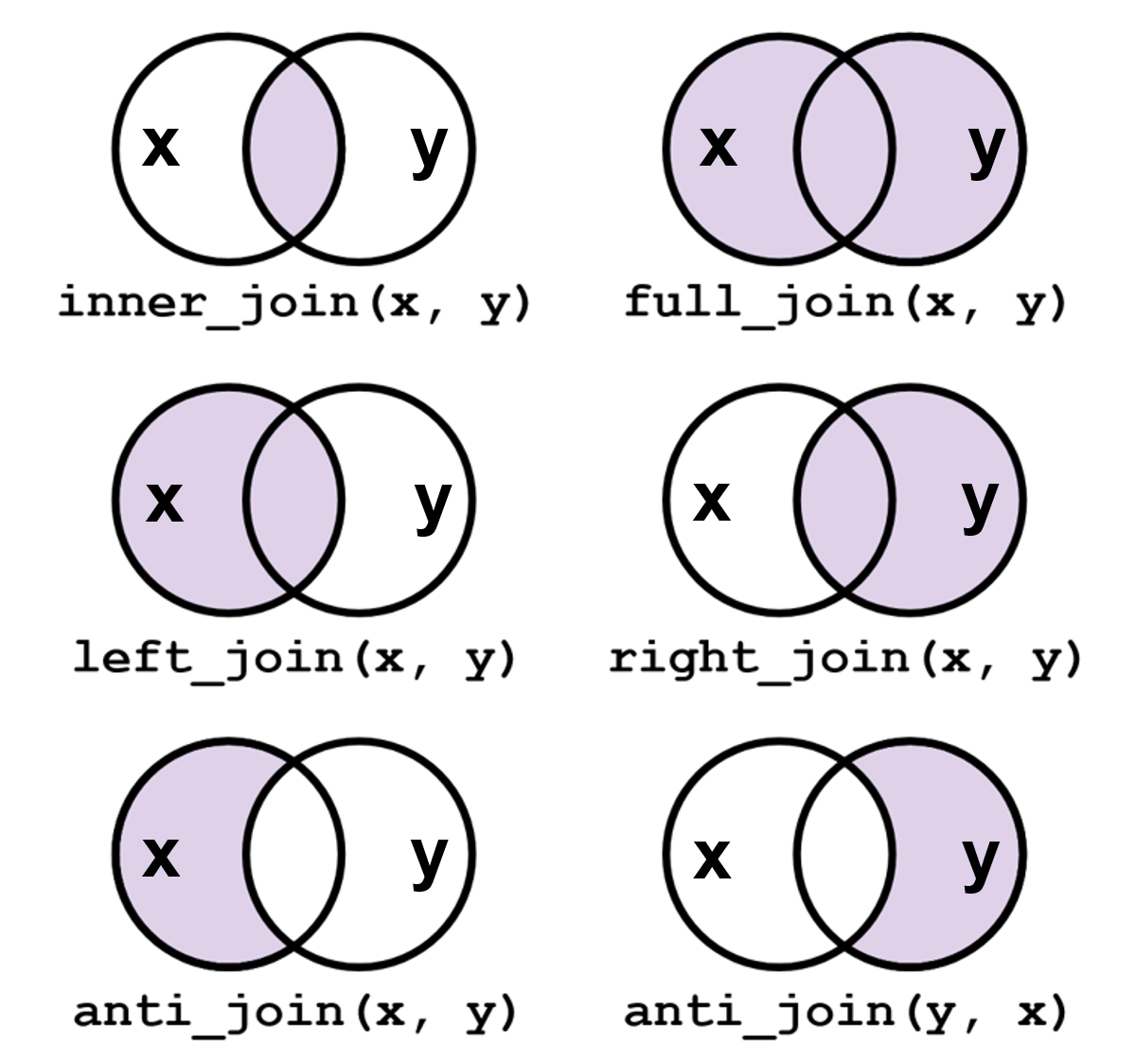
Une tâche courante dans l’analyse de données consiste à rassembler différents ensembles de données afin de pouvoir combiner les colonnes de deux (ou plusieurs) tableaux. Pour ce faire, on peut utiliser la famille de fonctions “join” du package “dplyr”. Il existe différents types de jointures entre une table X et une table Y :
La partie des tables conservée par la jointure est indiquée en violet sur le schéma. Afin de pouvoir effectuer ces jointures, les tables X et Y doivent avoir un champ commun. Généralement ce champ commun constitue la clef des tables à joindre. Par exemple : id_profil pour la table PROFIL. Pour DoneSol, les clefs des tables sont indiquées dans le dictionnaire de données.
Nous rajoutons un champ GER que nous remplissons avec les valeurs des champs cpcs, rp_95_ger et rp_2008_ger. Pour cela, nous allons utiliser la fonction “ifelse”.
ⓘ NOTE SUR LA FONCTION ifelse
ifelse(condition, valeur_si_vrai, valeur_si_faux)
avec :
- condition : une expression logique qui est évaluée pour chaque élément.
- valeur_si_vrai : la valeur à retourner si la condition est vraie.
- valeur_si_faux : la valeur à retourner si la condition est fausse.
profil$GER<-"NA" # création du champ GER vide (valeurs manquantes notées NA).
profil$GER<-ifelse(is.na(profil$GER), profil$GER, profil$label_RP2008) # remplace les NA par les valeurs RP2008
profil$GER<-ifelse(is.na(profil$GER), profil$label_RP95, profil$GER) # remplace les NA par les valeurs RP95
# Nous transformons la CPCS en RP dans un nouveau champ GER_cpcs:
profil$GER_cpcs<-profil$cpcs_nom
profil$GER_cpcs<-ifelse(profil$GER_cpcs %in% c("1111","2412", "1210"), "LITHOSOL",profil$GER_cpcs)
profil$GER_cpcs<-ifelse(profil$GER_cpcs %in% "9224", "FERSIALSOL_ELUVIQUE",profil$GER_cpcs)
profil$GER_cpcs<-ifelse(profil$GER_cpcs %in% c("9225","9222","9221", "9220","9215", "9214", "9213", "9212", "9211", "9210", "9200", "9000"), "FERSIALSOL",profil$GER_cpcs)
profil$GER_cpcs<-ifelse(profil$GER_cpcs %in% c("1112", "1140", "1141", "1142", "2440", "2441", "2442", "2443", "2410", "2411", "1100", "1000", "1150", "1151", "1152", "2450", "2451", "2452", "2453", "2400", "1110", "1162"), "REGOSOL",profil$GER_cpcs)
profil$GER_cpcs<-ifelse(profil$GER_cpcs %in% c("1120", "1121", "1122", "2420", "2421","2422", "2423"), "FLUVIOSOL",profil$cpcs_nom)
profil$GER_cpcs<-ifelse(profil$GER_cpcs %in% c("10000", "10100", "10110", "10111", "10112", "10113", "10114", "10115", "10120", "10121", "10122", "10123", "10124", "10130", "10131", "10132", "10133", "10134", "10140", "10141", "10142", "10143", "10200", "10210", "10211", "10212", "10213", "10214", "10215", "10216", "10217", "10220", "10221", "10222", "10223", "10230", "10231", "10232", "10233", "10234", "10235", "10240", "10241", "10242", "10243", "10244", "10245", "10246", "10250", "10251", "10252", "10253", "10300", "10310", "10311", "10312", "10313", "10314", "10315", "10316", "10317", "10320", "10321", "10322", "10330", "10331", "10332", "10333", "10334", "10335", "10340", "10341", "10342", "10343", "10344", "10350", "10351", "10352", "10353", "10360", "10361", "10362", "10363", "10364"), "FERRALLITISOL",profil$GER_cpcs)
profil$GER_cpcs<-ifelse(profil$GER_cpcs %in% c("11000", "11320", "11322", "11340","11341", "11342", "11350", "11360", "11361", "11362", "11300"), "REDOXISOL",profil$GER_cpcs)
profil$GER_cpcs<-ifelse(profil$GER_cpcs %in% c("11100", "11110", "11111", "11112", "11120", "11121", "11122", "11130", "11131", "11132"), "HISTOSOL",profil$GER_cpcs)
profil$GER_cpcs<-ifelse(profil$GER_cpcs %in% c("2210", "2211", "2212", "2213", "2000", "2200", "2210","2211","2212","2213", "2220","2230", "2320"), "RANKOSOL",profil$GER_cpcs)
profil$GER_cpcs<-ifelse(profil$GER_cpcs %in% c("1130", "1131", "1132", "2430", "2431", "2432","2433"), "COLLUVIOSOL",profil$GER_cpcs)
profil$GER_cpcs<-ifelse(profil$GER_cpcs %in% c("3000", "3100", "3110", "3111", "3112", "3113", "3114", "3120", "3121", "3122", "3123", "3124", "3125", "3200", "3210", "3211", "3212", "3213", "3214", "3220", "3221", "3222", "3223", "3224", "3225"), "VERTISOL",profil$GER_cpcs)
profil$GER_cpcs<-ifelse(profil$GER_cpcs %in% c("4000", "4100", "4110", "4200", "4210", "4211", "4212", "4213", "4220", "4221", "4222", "4223"), "ANDOSOL",profil$GER_cpcs)
profil$GER_cpcs<-ifelse(profil$GER_cpcs %in% c("5110", "5111", "5112", "5113", "5114", "5115"), "RENDOSOL",profil$GER_cpcs)
profil$GER_cpcs<-ifelse(profil$GER_cpcs %in% c("5120", "5121", "5122", "5123", "5124", "5220", "5221"), "CALCOSOL",profil$GER_cpcs)
profil$GER_cpcs<-ifelse(profil$GER_cpcs %in% c("5130"), "DOLOMITOSOL",profil$GER_cpcs)
profil$GER_cpcs<-ifelse(profil$GER_cpcs %in% c("5210", "5211", "5212", "5213", "5200"), "CALCISOL",profil$GER_cpcs)
profil$GER_cpcs<-ifelse(profil$GER_cpcs %in% c("5230", "5231", "5232"), "LEPTISMECTISOL",profil$GER_cpcs)
profil$GER_cpcs<-ifelse(profil$GER_cpcs %in% c("5300", "5310", "5320", "5321", "5322"), "GYPSOSOL",profil$GER_cpcs)
profil$GER_cpcs<-ifelse(profil$GER_cpcs %in% c("7110", "7111", "7113", "7114", "2140", "6231", "6232", "6233", "6234", "6235", "6410", "6411", "7000", "710", "7100", "7115", "7200", "7300", "7400", "7410", "7411", "7412","7413", "7414"), "BRUNISOL",profil$GER_cpcs)
profil$GER_cpcs<-ifelse(profil$GER_cpcs %in% c("7112"), "ALOCRISOL",profil$GER_cpcs)
profil$GER_cpcs<-ifelse(profil$GER_cpcs %in% c("7121"), "NEOLUVISOL",profil$GER_cpcs)
profil$GER_cpcs<-ifelse(profil$GER_cpcs %in% c("7120", "7122", "7123", "7124", "7125", "7126", "7127"), "LUVISOL",profil$GER_cpcs)
profil$GER_cpcs<-ifelse(profil$GER_cpcs %in% c("8000", "8100", "8110", "8111", "8112", "8113", "8114", "8115", "8120", "8121", "8122", "8123", "8124", "8125", "8130", "8131", "8132", "8140", "8141", "8142", "8200", "8210", "8220", "8300", "8310", "8311", "8312", "8320", "8330"), "PODZOSOL",profil$GER_cpcs)
profil$GER_cpcs<-ifelse(profil$GER_cpcs %in% c("11200", "11210", "11211", "11212", "11213", "11214", "11220", "11221", "11310", "11311","11312", "11313", "11314", "11330"), "REDUCTISOL",profil$GER_cpcs)
profil$GER_cpcs<-ifelse(profil$GER_cpcs %in% c("11321"), "PELOSOL",profil$GER_cpcs)
profil$GER_cpcs<-ifelse(profil$GER_cpcs %in% c("13000", "13100", "13200"), "PLANOSOL",profil$GER_cpcs)
profil$GER_cpcs<-ifelse(profil$GER_cpcs %in% c("12000", "12200", "12210", "12211", "12212", "12220", "12221", "12222", "12230", "12231", "12232"), "SODISOL",profil$GER_cpcs)
profil$GER_cpcs<-ifelse(profil$GER_cpcs %in% c("12100", "12110", "12111", "12112", "12113", "12114"), "SALISOL",profil$GER_cpcs)
profil$GER_cpcs<-ifelse(profil$GER_cpcs %in% c("2130", "2120"), "CRYOSOL",profil$GER_cpcs)
profil$GER_cpcs<-ifelse(profil$GER_cpcs %in% c("2460", "2461", "2462", "2463"), "ANTHROPOSOL",profil$GER_cpcs)
profil$GER_cpcs<-ifelse(profil$GER_cpcs %in% c("5000","5100", "1721", "5215", "6315", "6320","6321", "6322", "6323", "6324", "6325", "7116", "7170", "7425", "7710"), "ND",profil$GER_cpcs)
profil$GER_cpcs<-ifelse(profil$GER_cpcs %in% c("1111","2412", "1210"), "LITHOSOL",profil$GER_cpcs)
profil$GER_cpcs<-ifelse(profil$GER_cpcs %in% "9224", "FERSIALSOL_ELUVIQUE",profil$GER_cpcs)
profil$GER_cpcs<-ifelse(profil$GER_cpcs %in% c("9225","9222","9221", "9220","9215", "9214", "9213", "9212", "9211", "9210", "9200", "9000"), "FERSIALSOL",profil$GER_cpcs)
profil$GER_cpcs<-ifelse(profil$GER_cpcs %in% c("1112", "1140", "1141", "1142", "2440", "2441", "2442", "2443", "2410", "2411", "1100", "1000", "1150", "1151", "1152", "2450", "2451", "2452", "2453", "2400", "1110", "1162"), "REGOSOL",profil$GER_cpcs)
# Nous remplaçons les valeurs manquantes (NA) du champ GER par la valeur du champ GER_cpcs
profil$GER<-ifelse(is.na(profil$GER), profil$GER_cpcs, profil$GER) # remplace les NA par les valeurs CPCS transformées en RP
str(profil$GER)## chr [1:2894] "BRUNISOL" "BRUNISOL" "BRUNISOL" "COLLUVIOSOL" "BRUNISOL" ...
profil$GER<-as.factor(profil$GER) # Mise du champ GER en facteur
# Nous pouvons utiliser cette information pour refaire des regroupements si besoin.
table(profil$GER) # nombre de profils par GER##
## ALOCRISOL ALOCRISOL-REDOXISOL ANTHROPOSOL ARTIFICIEL
## 15 1 1
## BRUNISOL BRUNISOL MESOSATURE BRUNISOL OLIGO-SATURE
## 1815 18 3
## BRUNISOL SATURE BRUNISOL-REDOXISOL CALCISOL
## 9 44 226
## CALCISOL-REDOXISOL CALCOSOL COLLUVIOSOL
## 1 11 192
## COLLUVIOSOL-REDOXISOL CRYOSOL FLUVIOSOL
## 8 2 83
## FLUVIOSOL-REDOXISOL HISTOSOL MESIQUE LUVISOL
## 1 1 98
## LUVISOL DEGRADE LUVISOL TRONQUE LUVISOL-REDOXISOL
## 1 1 41
## ND NEOLUVISOL NEOLUVISOL-REDOXISOL
## 5 189 20
## PELOSOL PLANOSOL TYPIQUE PODZOSOL
## 9 1 4
## PODZOSOL MEUBLE RANKOSOL REDOXISOL
## 1 30 12
## REDUCTISOL REDUCTISOL STAGNIQUE REGOSOL
## 4 1 3
## RENDOSOL
## 2
# remplace les valeurs manquantes (NA) par ND pour le champ GER de la table profil
profil$GER[is.na(profil$GER)]<-"ND"
# Supression des champs inutiles dans la table profil
profil <- subset(profil, select = -c(cpcs_nom, rp_95_ger, rp_2008_ger, label_RP2008, label_RP95, label_cpcs, GER_cpcs, occup_codee))
# visualisation des champs de la table PROFIL
str(profil)## 'data.frame': 2894 obs. of 8 variables:
## $ id_profil : int 110185 132400 96907 84414 131978 90327 137960 110218 90246 96908 ...
## $ altitude : chr "" "" "105.0" "151.0" ...
## $ date_p : chr "01/10/1975" "15/04/1990" "14/08/1986" "17/09/1991" ...
## $ drai_nat_p: int NA NA NA NA 7 NA 6 NA NA NA ...
## $ arret : int 1 2 1 1 1 1 1 1 1 1 ...
## $ prof_arret: int NA NA NA NA NA NA NA NA NA NA ...
## $ landuse : Factor w/ 7 levels "Forets","Prairies_permanentes",..: 2 3 3 3 3 3 3 2 3 6 ...
## $ GER : Factor w/ 34 levels "ALOCRISOL","ALOCRISOL-REDOXISOL",..: 4 4 4 12 4 4 4 18 4 4 ...
#supression des fichiers inutiles pour la suite
rm(dico_cpcs)
rm(dico_ger2008)
rm(dico_ger95)
rm(dico)
# Visualisation des données
library(ggplot2)
library(dplyr)
profil %>%
# compter le nombre de profils par GER
count(GER, sort = TRUE) %>%
# Réorganisez les GER en fonction du nombre de profils
mutate(GER = forcats::fct_reorder(.f = GER, .x = n, .desc = TRUE)) %>%
# Faire le graphique
ggplot(aes(x = n, y = GER)) +
geom_col() +
xlab("Nombre de profils") +
geom_text(aes(label = n), size = 3, fontface = "bold", col="red", hjust=0) + # rajout des labels
coord_cartesian(clip = "off") + # pour ne pas que les labels soient coupés
theme_minimal()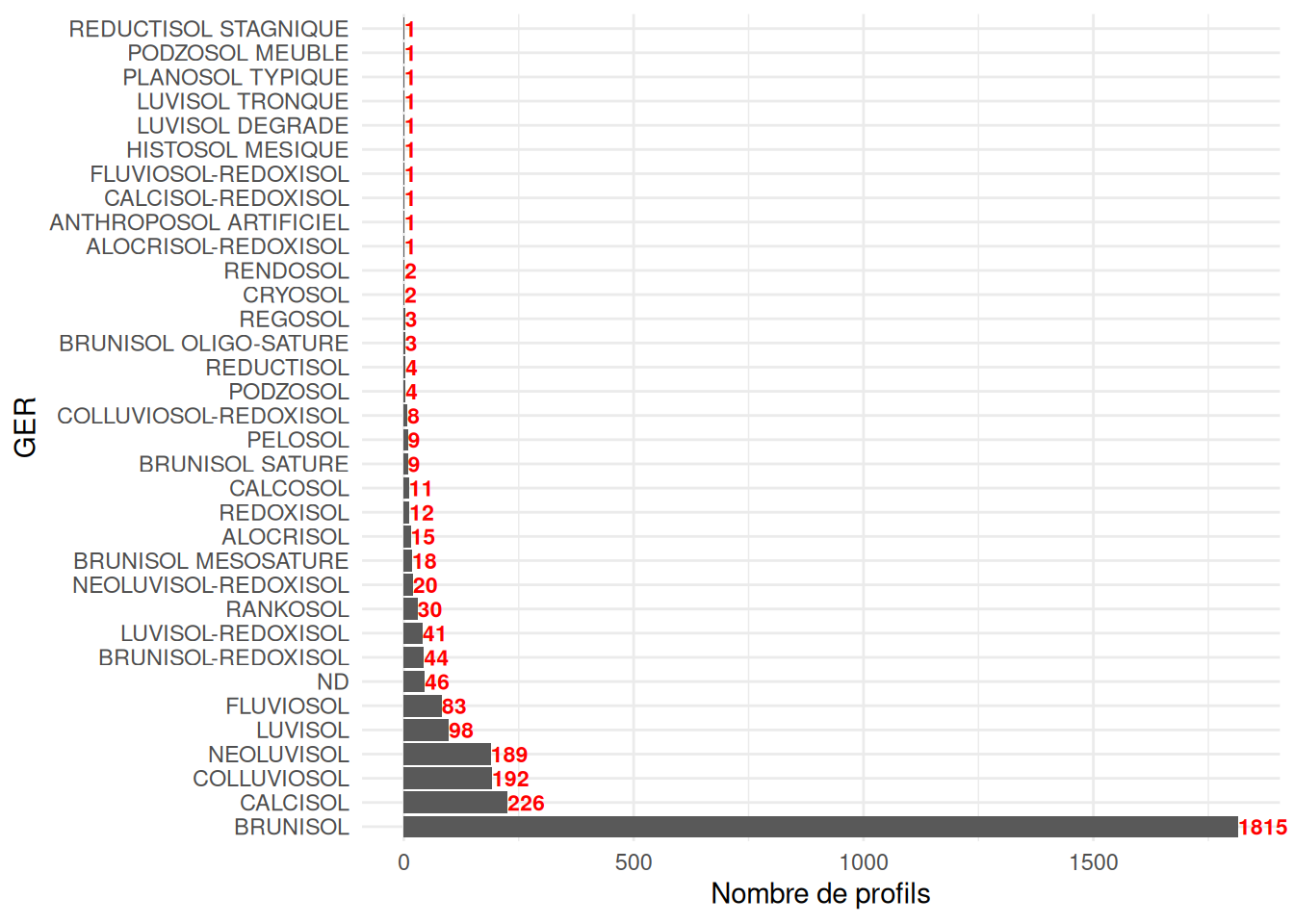
On peut le coder en dplyr
recodes <- list(
LITHOSOL = c("1111","2412","1210"),
FERSIALSOL_ELUVIQUE = c("9224"),
FERSIALSOL = c(
"9225","9222","9221","9220","9215","9214","9213","9212","9211",
"9210","9200","9000"
),
REGOSOL = c(
"1112","1140","1141","1142","2440","2441","2442","2443","2410",
"2411","1100","1000","1150","1151","1152","2450","2451","2452",
"2453","2400","1110","1162"
),
FLUVIOSOL = c("1120","1121","1122","2420","2421","2422","2423"),
FERRALLITISOL = c(
"10000","10100","10110","10111","10112","10113","10114","10115",
"10120","10121","10122","10123","10124","10130","10131","10132",
"10133","10134","10140","10141","10142","10143","10200","10210",
"10211","10212","10213","10214","10215","10216","10217","10220",
"10221","10222","10223","10230","10231","10232","10233","10234",
"10235","10240","10241","10242","10243","10244","10245","10246",
"10250","10251","10252","10253","10300","10310","10311","10312",
"10313","10314","10315","10316","10317","10320","10321","10322",
"10330","10331","10332","10333","10334","10335","10340","10341",
"10342","10343","10344","10350","10351","10352","10353","10360",
"10361","10362","10363","10364"
),
REDOXISOL = c(
"11000","11320","11322","11340","11341","11342","11350","11360",
"11361","11362","11300"
),
HISTOSOL = c(
"11100","11110","11111","11112","11120","11121","11122",
"11130","11131","11132"
),
RANKOSOL = c(
"2210","2211","2212","2213","2000","2200","2220","2230","2320"
),
COLLUVIOSOL = c(
"1130","1131","1132","2430","2431","2432","2433"
),
VERTISOL = c(
"3000","3100","3110","3111","3112","3113","3114","3120","3121",
"3122","3123","3124","3125","3200","3210","3211","3212","3213",
"3214","3220","3221","3222","3223","3224","3225"
),
ANDOSOL = c(
"4000","4100","4110","4200","4210","4211","4212","4213",
"4220","4221","4222","4223"
),
RENDOSOL = c("5110","5111","5112","5113","5114","5115"),
CALCOSOL = c("5120","5121","5122","5123","5124","5220","5221"),
DOLOMITOSOL = c("5130"),
CALCISOL = c("5210","5211","5212","5213","5200"),
LEPTISMECTISOL = c("5230","5231","5232"),
GYPSOSOL = c("5300","5310","5320","5321","5322"),
BRUNISOL = c(
"7110","7111","7113","7114","2140","6231","6232","6233","6234",
"6235","6410","6411","7000","710","7100","7115","7200","7300",
"7400","7410","7411","7412","7413","7414","7116","7170","7425",
"7710"
),
ALOCRISOL = c("7112"),
NEOLUVISOL = c("7121"),
LUVISOL = c("7120","7122","7123","7124","7125","7126","7127"),
PODZOSOL = c(
"8000","8100","8110","8111","8112","8113","8114","8115","8120",
"8121","8122","8123","8124","8125","8130","8131","8132","8140",
"8141","8142","8200","8210","8220","8300","8310","8311","8312",
"8320","8330"
),
REDUCTISOL = c(
"11200","11210","11211","11212","11213","11214","11220","11221",
"11310","11311","11312","11313","11314","11330"
),
PELOSOL = c("11321"),
PLANOSOL = c("13000","13100","13200"),
SODISOL = c(
"12000","12200","12210","12211","12212","12220","12221",
"12222","12230","12231","12232"
),
SALISOL = c("12100","12110","12111","12112","12113","12114"),
CRYOSOL = c("2130","2120"),
ANTHROPOSOL = c("2460","2461","2462","2463"),
ND = c(
"5000","5100","1721","5215","6315","6320","6321","6322","6323",
"6324","6325","7116","7170","7425","7710"
)
)
library(dplyr)
library(purrr)
profil <- profil %>%
mutate(GER_cpcs =
map_chr(cpcs_nom, ~ {
match <- names(recodes)[map_lgl(recodes, ~ .x %in% .y)]
ifelse(length(match) == 0, cpcs_nom, match)
})
)Sur la base de ce graphique, nous pouvons décider de regrouper les classes avec peu de profils dans une classe “autre”.
3.1.3 Importation de la table POI
3.1.3.1 Importation de POI
La table POI contient les coordonnées X,Y des points dans différentes projections. Nous allons utiliser par la suite la projection en lambert 93 en mètres.
poi <- read.csv2('donnees/jour1/donesol/poi.csv', sep=";")
poi <- poi[,c(3,7,8)] # sélection des coordonnées en lambert 93
# Mettre les coordonnées en numérique
poi$x_l93<-as.numeric(poi$x_l93)
poi$y_l93<-as.numeric(poi$y_l93)
str(poi) # visualiser la liste des champs de la table POI## 'data.frame': 2892 obs. of 3 variables:
## $ id_profil: int 382 388 397 413 426 433 438 446 454 458 ...
## $ x_l93 : num 440655 440742 440515 440648 440986 ...
## $ y_l93 : num 6782309 6782233 6782611 6782483 6782778 ...3.1.3.2 Option : Cartogramme des points
Nous allons projeter les points XY sur le département de la Mayenne pour visualiser leur répartition. Nous commençons par importer les contours des Pays de la Loire qui est la région où se trouve notre zone d’étude.
Nous allons ici utiliser les données provenant du site de l’IGN pour obtenir un fond de carte. Nous pouvons les télécharger sur : https://github.com/ThinkR-open/iframe.illustrations/blob/master/data_article_tmap/DEPARTEMENT.zip
Il faudra décompresser le fichier DEPARTEMENT.zip, dans un dossier departement/.
Pour ce TD, le dossier “departement” est déjà présent dans les documents fournis.
#Nous chargeons les packages nécessaires
library(ggplot2)
library(sf)
library("ggspatial")
# Nous importons la couche departement en lambert 93
departements_l93 <- read_sf("donnees/jour1/departement/DEPARTEMENT.shp")
# Visualisation de la carte des départements
ggplot(data = departements_l93) +
geom_sf() +
scale_y_continuous(labels = ~ paste0(., '\u00B0', "N"))+ # permet l'affichage du symbole°
scale_x_continuous(labels = ~ paste0(., '\u00B0', "N"))
# Nous sélectionnons le département de la Mayenne
mayenne <- departements_l93 %>%
dplyr::filter(NOM_DEPT == "MAYENNE")
# Visualisation du département de la Mayenne
ggplot() +
geom_sf(data = mayenne)+
scale_y_continuous(labels = ~ paste0(., '\u00B0', "N"))+ # permet l'affichage du symbole°
scale_x_continuous(labels = ~ paste0(., '\u00B0', "N"))
# Nous vérifions le système de projection. Il doit être en lambert 93.
sf::st_crs(mayenne)## Coordinate Reference System:
## User input: RGF93 Lambert 93
## wkt:
## PROJCRS["RGF93 Lambert 93",
## BASEGEOGCRS["RGF93 geographiques (dms)",
## DATUM["Reseau Geodesique Francais 1993 v1",
## ELLIPSOID["GRS 1980",6378137,298.257222101,
## LENGTHUNIT["metre",1]]],
## PRIMEM["Greenwich",0,
## ANGLEUNIT["degree",0.0174532925199433]],
## ID["IGNF","RGF93G"]],
## CONVERSION["LAMBERT-93",
## METHOD["Lambert Conic Conformal (2SP)",
## ID["EPSG",9802]],
## PARAMETER["Latitude of false origin",46.5,
## ANGLEUNIT["degree",0.0174532925199433],
## ID["EPSG",8821]],
## PARAMETER["Longitude of false origin",3,
## ANGLEUNIT["degree",0.0174532925199433],
## ID["EPSG",8822]],
## PARAMETER["Latitude of 1st standard parallel",44,
## ANGLEUNIT["degree",0.0174532925199433],
## ID["EPSG",8823]],
## PARAMETER["Latitude of 2nd standard parallel",49,
## ANGLEUNIT["degree",0.0174532925199433],
## ID["EPSG",8824]],
## PARAMETER["Easting at false origin",700000,
## LENGTHUNIT["metre",1],
## ID["EPSG",8826]],
## PARAMETER["Northing at false origin",6600000,
## LENGTHUNIT["metre",1],
## ID["EPSG",8827]]],
## CS[Cartesian,2],
## AXIS["easting (X)",east,
## ORDER[1],
## LENGTHUNIT["metre",1]],
## AXIS["northing (Y)",north,
## ORDER[2],
## LENGTHUNIT["metre",1]],
## USAGE[
## SCOPE["NATIONALE A CARACTERE LEGAL"],
## AREA["FRANCE METROPOLITAINE (CORSE COMPRISE)"],
## BBOX[41,-5.5,52,10]],
## ID["IGNF","LAMB93"]]
# Nous convertissons les données XY en fichier spatial
poi2 <- st_as_sf(poi, coords = c("x_l93", "y_l93"), crs = st_crs(mayenne))
# Nous projetons les points sur le fond de carte
ggplot() +
geom_sf(data = mayenne) +
geom_sf(data = poi2)+
scale_y_continuous(labels = ~ paste0(., '\u00B0', "N"))+ # permet l'affichage du symbole°
scale_x_continuous(labels = ~ paste0(., '\u00B0', "N"))
# Pour ne conserver que les points de la zone d'étude
poi_mayenne <- st_join(poi2, mayenne, left = FALSE)
# carte de répartition des points en Mayenne
ggplot() +
geom_sf(data = mayenne) +
geom_sf(data = poi_mayenne)+
scale_y_continuous(labels = ~ paste0(., '\u00B0', "N"))+ # permet l'affichage du symbole°
scale_x_continuous(labels = ~ paste0(., '\u00B0', "N"))+
# ajout d'une échelle
annotation_scale(location = "bl", # position de la barre d'échelle
line_width = 0.5, # largeur de ligne pour la barre d'échelle
style="ticks", # style de la barre d'échelle
width_hint = 0.1, # dimension de l'échelle (ici 10 km)
pad_x = unit(0, "in"), pad_y = unit(0, "in"),) + # Distance entre la barre d'échelle et le bord du graphique
# ajout d'une flèche Nord
annotation_north_arrow(location = "tl", # position de la flèche
which_north = "true",
pad_x = unit(-0.09, "in"), pad_y = unit(0.1, "in"),
style = ggspatial::north_arrow_nautical( # choix du style de la flèche
fill = c("grey40", "white"), # choix de la couleur de la flèche
line_col = "grey20",
text_family = "ArcherPro Book"))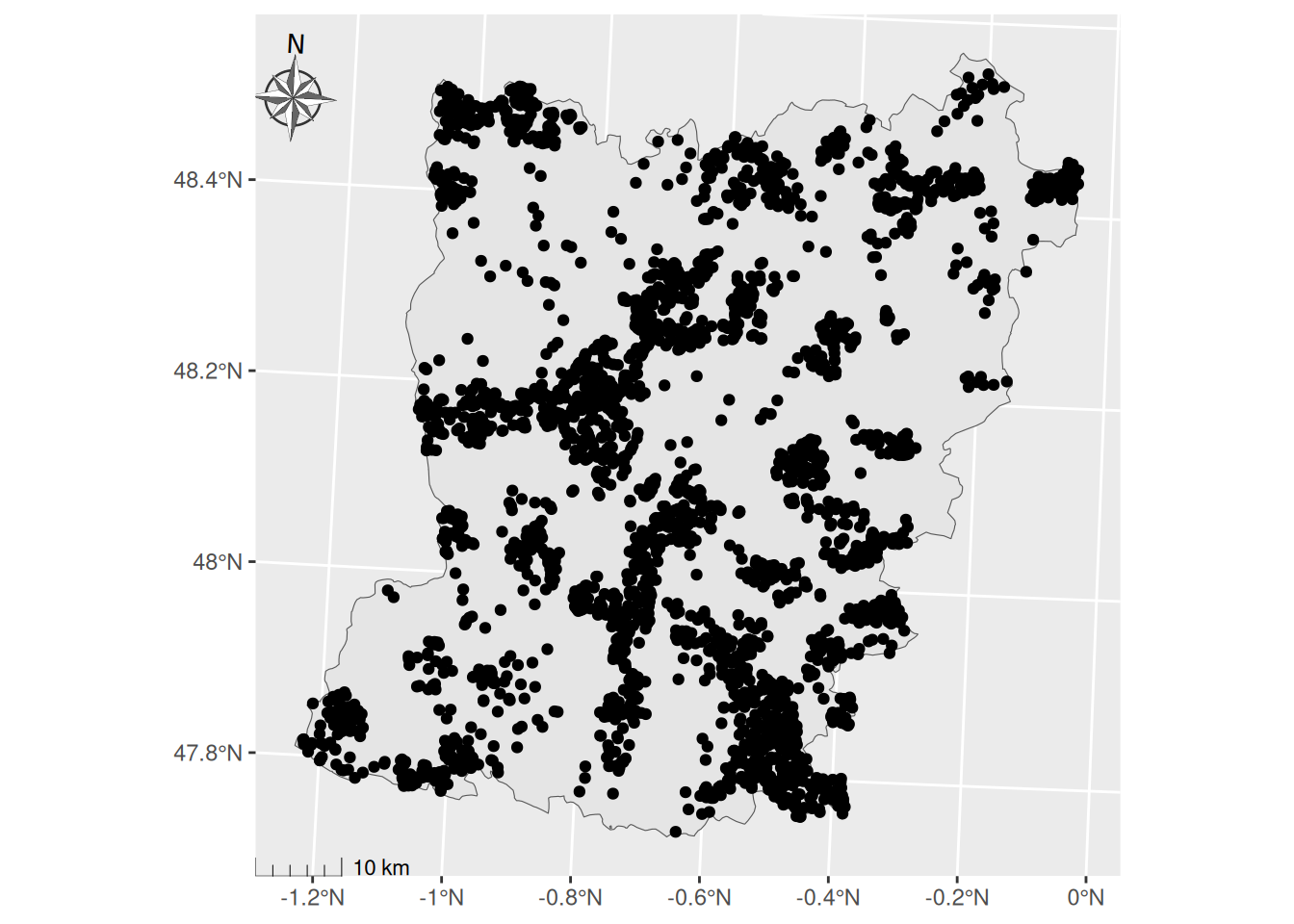
3.1.4 I.4. Importation de la table HORIZON
La table HORIZON décrit les horizons du profil. Toutes les observations faites sur un horizon sont reportées dans cette table.
horizon <- read.csv2('donnees/jour1/donesol/horizon.csv', sep=";")Nous sélectionnons les champs que nous souhaitons garder pour la suite. Vous pouvez modifier ce code pour sélectionner les champs de la table HORIZON qui vous intéressent. Il est conseillé de conserver le nom des champs identique à celui du dictionnaire de données pour éviter des confusion par la suite.
horizon <- data.frame("id_profil"=horizon$id_profil, # identifiant du profil auquel appartient l'horizon
"no_horizon"=horizon$no_horizon, # numéro de l'horizon dans le profil
"cpcs_nom"=horizon$cpcs_nom, # lettre code de l'horizon selon la CPCS
"rp_95_nom"=horizon$rp_95_nom, # lettre code de l'horizon selon le RP95
"rp_2008_nom"=horizon$rp_2008_nom, # lettre code de l'horizon selon le RP2008
"prof_sup_min"=horizon$prof_sup_min, # profondeur minimum d'apparition de l'horizon
"prof_sup_moy"=horizon$prof_sup_moy, # profondeur moyenne d'apparition de l'horizon
"prof_sup_max"=horizon$prof_sup_max, # profondeur maximum d'apparition de l'horizon
"prof_inf_min"=horizon$prof_inf_min,# profondeur minimum de disparition de l'horizon
"prof_inf_moy"=horizon$prof_inf_moy,# profondeur moyenne de disparition de l'horizon
"prof_inf_max"=horizon$prof_inf_max,# profondeur maximum de disparition de l'horizon
"textur"=horizon$textur, # classe de texture selon le triangle de la table PROFIL
"abondance_eg"=horizon$abondance_eg, # abondance totale des éléments grossiers (EG)
"abondance_eg_prin"=horizon$abondance_eg_prin, # abondance des EG principaux
"abondance_eg_sec"=horizon$abondance_eg_sec) # abondance des EG secondaires
str(horizon) # visualiser la liste des champs de la table HORIZON## 'data.frame': 10208 obs. of 15 variables:
## $ id_profil : int 86878 3838 132232 125922 4099 132384 85427 90159 85646 124318 ...
## $ no_horizon : int 4 3 4 1 4 1 4 1 2 3 ...
## $ cpcs_nom : chr "C2G" "" "" "Apg" ...
## $ rp_95_nom : chr "" "S2" "Cg" "" ...
## $ rp_2008_nom : chr "" "" "" "" ...
## $ prof_sup_min : chr "" "" "" "" ...
## $ prof_sup_moy : chr "120.0" "40.0" "57.0" "0.0" ...
## $ prof_sup_max : chr "" "" "" "" ...
## $ prof_inf_min : chr "" "" "" "" ...
## $ prof_inf_moy : chr "" "75.0" "70.0" "35.0" ...
## $ prof_inf_max : chr "" "" "" "" ...
## $ textur : chr "LA" "LMS" "LA" "LSA" ...
## $ abondance_eg : chr "20.0" "0.0" "" "" ...
## $ abondance_eg_prin: chr "" "" "" "" ...
## $ abondance_eg_sec : chr "" "" "" "" ...Il est important de prendre tous les champs concernant les profondeurs des horizons. Ces champs nous seront utiles dans la partie V.
3.1.5 I.5. Importation de la table PRELEVEMENT
La table PRELEVEMENT permet de décrire un prélèvement sur le terrain. Cette table pourrait nous être utile pour compléter les profondeurs des horizons lorsque celles-ci sont manquantes.
prelevement <- read.csv2('donnees/jour1/donesol/prelevement.csv', sep=";")
# Nous choisissons les champs à conserver :
prelevement <- data.frame("id_prelevement"=prelevement$id_prelevement, # identifiant du prélèvement
"id_profil"=prelevement$id_profil, # identifiant du profil auquel appartient le prélèvement
"no_horizon"=prelevement$no_horizon, # numéro de l'horizon auquel appartient le prélèvement
"prof_base"=prelevement$prof_base, # profondeur de la base du prélèvement
"prof_sommet"=prelevement$prof_sommet) # profondeur du sommet du prélèvement
str(prelevement) # visualiser la liste des champs de la table ANALYSE## 'data.frame': 8726 obs. of 5 variables:
## $ id_prelevement: int 114984 219707 159411 47442 205657 149534 219172 108741 216756 205721 ...
## $ id_profil : int 82301 139302 123946 4179 124318 90316 124167 10546 90129 124328 ...
## $ no_horizon : int 1 4 1 2 1 2 3 2 2 4 ...
## $ prof_base : chr "40.0" "100.0" "31.0" "40.0" ...
## $ prof_sommet : chr "0.0" "75.0" "0.0" "30.0" ...3.1.6 I.6. Importation de la table ANALYSE
La table ANALYSE contient des informations sur le laboratoire d’analyse et des généralités sur les résultats des analyses réalisées sur les horizons. Nous allons nous en servir pour faire le lien avec la table PRELEVEMENT importée précédemment.
analyse <- read.csv2('donnees/jour1/donesol/analyse.csv', sep=";")
#Nous choisissons les champs à conserver :
analyse <- data.frame("id_profil"=analyse$id_profil, # identifiant du profil auquel appartient l'analyse
"no_horizon"=analyse$no_horizon, # numéro de l'horizon auquel appartient l'analyse
"id_analyse"=analyse$id_analyse, # identifiant de l'analyse
"id_prelevement"=analyse$id_prelevement) # identifiant du prélèvement
str(analyse) # visualiser la liste des champs de la table ANALYSE## 'data.frame': 9335 obs. of 4 variables:
## $ id_profil : int 382 382 382 388 388 388 388 397 397 397 ...
## $ no_horizon : int 1 2 3 1 2 3 4 1 2 3 ...
## $ id_analyse : int 130340 130341 130342 130346 130347 130348 130349 130308 130309 130310 ...
## $ id_prelevement: int 117005 117006 117007 117011 117012 117013 117014 116975 116976 116977 ...Nous fusionnons ensuite les tables ANALYSE et PRELEVEMENT de façon à avoir les profondeurs de prélèvement dans la table ANALYSE.
analyse<-full_join(analyse, prelevement, by=c("id_prelevement", "id_profil", "no_horizon")) # jointure entre ANALYSE et PRELEVEMENT
# Nous mettons les champs de profondeurs en numérique
analyse$prof_base<-as.numeric(analyse$prof_base)
analyse$prof_sommet<-as.numeric(analyse$prof_sommet)
# Nous affichons le nouveau contenu de la table ANALYSE :
summary(analyse)## id_profil no_horizon id_analyse id_prelevement
## Min. : 382 Min. :1.000 Min. : 2925 Min. : 2922
## 1st Qu.: 84582 1st Qu.:1.000 1st Qu.:122710 1st Qu.:111392
## Median : 90456 Median :2.000 Median :136106 Median :149608
## Mean : 93683 Mean :2.274 Mean :138399 Mean :140336
## 3rd Qu.:126114 3rd Qu.:3.000 3rd Qu.:173284 3rd Qu.:204393
## Max. :139441 Max. :6.000 Max. :249765 Max. :272719
## NA's :1 NA's :600
## prof_base prof_sommet
## Min. : 0.00 Min. : -1.00
## 1st Qu.: 30.00 1st Qu.: 0.00
## Median : 50.00 Median : 30.00
## Mean : 62.22 Mean : 34.08
## 3rd Qu.: 85.00 3rd Qu.: 55.00
## Max. :760.00 Max. :200.00
## NA's :1267 NA's :600
# Nous supprimons la table PRELEVEMENT devenue inutile :
rm(prelevement)Cette table ANALYSE sera utilisée dans la partie V lorsque nous travaillerons sur les profondeurs des horizons.
3.1.7 I.7. Importation de la table RESULTAT_ANALYSE
La table RESULTAT_ANALYSE contient l’ensemble des résultats des analyses réalisées sur les échantillons de sols.
resultat_analyse <- read.csv2('donnees/jour1/donesol/resultat_analyse.csv', sep=";")
str(resultat_analyse) # visualiser la liste des champs de la table RESULTAT_ANALYSE## 'data.frame': 80470 obs. of 8 variables:
## $ id_resultat : int 1539548 2093510 1211236 1528944 1204905 1369230 1213579 1535124 1745592 2088927 ...
## $ determination : chr "p_ass" "c_n" "ca_ech" "na_ech" ...
## $ valeur : chr "0.081" "9.3" "1.61" "0.049" ...
## $ unite : chr "g/kg" "" "cmol+/kg" "cmol+/kg" ...
## $ precision_r : logi NA NA NA NA NA NA ...
## $ id_analyse : int 127756 54764 166289 127075 165494 171704 166561 166621 188240 54624 ...
## $ id_methode : int 198 1 106 106 20 20 106 106 71 14 ...
## $ id_methode_physique: int NA NA NA NA NA NA NA NA NA NA ...3.1.8 I.8. Importation des données de granulométrie
Pour la granulométrie, les données sont stockées dans 3 tables :
La table RESULTAT_ANALYSE_GRANULO contient l’ensemble des résultats des analyses granulométriques réalisées sur les échantillons de sols.
La table ENS_RESULTAT_ANALYSE_GRANULO décrit les différentes méthodes utilisées lors de l’analyse granulométrique. Cette table est en lien avec la table de métadonnées METHODE_ANALYSE_GRANULO.
La table PREPARATION_GRANULO décrit les différentes préparations de l’échantillon avant l’analyse granulométrique. Par exemple, cette table nous est utile pour savoir si l’échantillon a été décarbonaté ou non avant l’analyse granulométrique.
resultat_analyse_granulo <- read.csv2('donnees/jour1/donesol/resultat_analyse_granulo.csv', sep=";")
ens_resultat_analyse_granulo <- read.csv2('donnees/jour1/donesol/ens_resultat_analyse_granulo.csv', sep=";")
preparation_granulo <- read.csv2('donnees/jour1/donesol/preparation_granulo.csv', sep=";")3.1.9 I.9. Importation de la table RESULTAT_EG
La table RESULTAT_EG contient l’ensemble des résultats de mesure de la quantité d’éléments grossiers réalisée sur les échantillons de sol. On appelle éléments grossiers toute fraction granulométrique supérieure à 2 mm.
resultat_eg <- read.csv2('donnees/jour1/donesol/resultat_eg.csv', sep=";")
# on sélectionne les champs à conserver
resultat_eg <- data.frame("id_resultat"=resultat_eg$id_resultat, # identifiant du résultat d'analyse
"id_analyse"=resultat_eg$id_analyse, # identifiant de l'analyse
"prc_mass_tot"=resultat_eg$prc_mass_tot, # % massique total des EG
"valeur"=resultat_eg$valeur) # % des EG
# Mise en numérique des champs "prc_mass_tot" et "valeur"
resultat_eg$prc_mass_tot <- as.numeric(resultat_eg$prc_mass_tot)
resultat_eg$valeur <- as.numeric(resultat_eg$valeur)
summary(resultat_eg)## id_resultat id_analyse prc_mass_tot valeur
## Min. : 298 Min. : 2925 Min. : 0.00 Min. : 0.000
## 1st Qu.: 64944 1st Qu.:126592 1st Qu.: 4.00 1st Qu.: 0.000
## Median : 65259 Median :127261 Median : 5.00 Median : 0.000
## Mean : 63066 Mean : 98198 Mean :16.77 Mean : 1.831
## 3rd Qu.:110076 3rd Qu.:127601 3rd Qu.:20.00 3rd Qu.: 0.000
## Max. :110237 Max. :128005 Max. :95.00 Max. :60.000
## NA's :356 NA's :2493.1.10 Option : abondance des éléments grossiers
Pour l’abondance des éléments grossiers, nous allons utiliser le champ “abondance_eg” de la table HORIZON. Lorsque ce champ est vide, nous allons le compléter avec la somme des champs “abondange_eg_prin” + “abondance_eg_sec” de la table HORIZON.
# On met les champs d'abondance des EG en numérique
horizon$abondance_eg <- as.numeric(horizon$abondance_eg)
horizon$abondance_eg_prin <- as.numeric(horizon$abondance_eg_prin)
horizon$abondance_eg_sec <- as.numeric(horizon$abondance_eg_sec)
# On sort les statistiques du champ abondance_eg
summary(horizon$abondance_eg)## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 0.00 5.00 10.00 20.01 25.00 99.00 3625
# Nous rajoutons un champ "SumEG" contenant la somme des champs abondance_eg_prin + abondance_eg_sec
horizon$SumEG <- ifelse(is.na(horizon$abondance_eg_prin) & is.na(horizon$abondance_eg_sec),
horizon$SumEG <- NA,
ifelse(is.na(horizon$abondance_eg_prin),
horizon$SumEG <- 0 + horizon$abondance_eg_sec,
horizon$abondance_eg_prin + horizon$abondance_eg_sec))
# Nous remplaçons les NA du champ "abondance_eg" par "SumEG" si celui-ci n'est pas vide
horizon$abondance_eg <-ifelse(is.na(horizon$abondance_eg),
horizon$SumEG,
horizon$abondance_eg)
summary(horizon$abondance_eg)## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 0.00 5.00 10.00 20.08 25.00 100.00 3586Il reste encore beaucoup de données manquantes dans le champ “abondance_eg”. Nous allons essayer de le compléter avec les données de la table RESULTAT_EG. Pour récupérer les identifants de l’horizon sur la table RESULTAT_EG, nous faisons une jointure avec la table ANALYSE.
# jointure entre ANALYSE et RESULTAT_EG
resultat_eg<-full_join(analyse,
resultat_eg,
by="id_analyse")
summary(resultat_eg)## id_profil no_horizon id_analyse id_prelevement
## Min. : 382 Min. :1.000 Min. : 2925 Min. : 2922
## 1st Qu.: 84468 1st Qu.:1.000 1st Qu.:123074 1st Qu.:112902
## Median : 90397 Median :2.000 Median :130304 Median :149162
## Mean : 93123 Mean :2.268 Mean :137994 Mean :139324
## 3rd Qu.:126085 3rd Qu.:3.000 3rd Qu.:172930 3rd Qu.:197141
## Max. :139441 Max. :6.000 Max. :249765 Max. :272719
## NA's :1 NA's :600
## prof_base prof_sommet id_resultat prc_mass_tot
## Min. : 0.0 Min. : -1.00 Min. : 298 Min. : 0.00
## 1st Qu.: 30.0 1st Qu.: 0.00 1st Qu.: 64944 1st Qu.: 4.00
## Median : 50.0 Median : 30.00 Median : 65259 Median : 5.00
## Mean : 62.1 Mean : 33.87 Mean : 63066 Mean :16.77
## 3rd Qu.: 83.0 3rd Qu.: 53.00 3rd Qu.:110076 3rd Qu.:20.00
## Max. :760.0 Max. :200.00 Max. :110237 Max. :95.00
## NA's :1267 NA's :600 NA's :9087 NA's :9443
## valeur
## Min. : 0.000
## 1st Qu.: 0.000
## Median : 0.000
## Mean : 1.831
## 3rd Qu.: 0.000
## Max. :60.000
## NA's :9336Nous allons compléter le champ “prc_mass_tot” avec le champ “valeur” lorsque le champ “prc_mass_tot” est vide.
resultat_eg$prc_mass_tot<-ifelse(is.na(resultat_eg$prc_mass_tot),
resultat_eg$valeur,
resultat_eg$prc_mass_tot)
summary(resultat_eg$prc_mass_tot)## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 0.000 0.000 0.000 7.979 5.000 95.000 9087Nous allons compléter le champ “abondance_eg” de la table HORIZON lorsque celui-ci est vide avec le champ “prc_mass_tot” de la table RESULTAT_EG.
resultat_eg <- data.frame("id_profil"=resultat_eg$id_profil,
"no_horizon"=resultat_eg$no_horizon,
"prc_mass_tot"=resultat_eg$prc_mass_tot) # % massique total des EG
# jointure entre HORIZON et RESULTAT_EG
horizon<-left_join(horizon, resultat_eg, by=c('id_profil','no_horizon'))
# suppression des lignes en doubles
horizon<-horizon[!duplicated(horizon), ]
# Nous remplaçons les valeurs vides du champ "abondance_eg" par
# les données du champ "prc_mass_tot" quand celui-ci n'est pas vide
horizon$abondance_eg<-ifelse(is.na(horizon$abondance_eg),
horizon$prc_mass_tot,
horizon$abondance_eg)
summary(horizon$abondance_eg)## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 0.00 5.00 10.00 19.93 25.00 100.00 3582Nous relectionnons les champs de la table HORIZON que nous souhaitons conserver.
horizon <- data.frame("id_profil"=horizon$id_profil,
"no_horizon"=horizon$no_horizon,
"cpcs_nom"=horizon$cpcs_nom,
"rp_95_nom"=horizon$rp_95_nom,
"rp_2008_nom"=horizon$rp_2008_nom,
"prof_sup_min"=horizon$prof_sup_min,
"prof_sup_moy"=horizon$prof_sup_moy,
"prof_sup_max"=horizon$prof_sup_max,
"prof_inf_min"=horizon$prof_inf_min,
"prof_inf_moy"=horizon$prof_inf_moy,
"prof_inf_max"=horizon$prof_inf_max,
"textur"=horizon$textur,
"abondance_eg"=horizon$abondance_eg)
str(horizon) # visualiser la liste des champs de la table HORIZON## 'data.frame': 10282 obs. of 13 variables:
## $ id_profil : int 86878 3838 132232 125922 4099 132384 85427 90159 85646 124318 ...
## $ no_horizon : int 4 3 4 1 4 1 4 1 2 3 ...
## $ cpcs_nom : chr "C2G" "" "" "Apg" ...
## $ rp_95_nom : chr "" "S2" "Cg" "" ...
## $ rp_2008_nom : chr "" "" "" "" ...
## $ prof_sup_min: chr "" "" "" "" ...
## $ prof_sup_moy: chr "120.0" "40.0" "57.0" "0.0" ...
## $ prof_sup_max: chr "" "" "" "" ...
## $ prof_inf_min: chr "" "" "" "" ...
## $ prof_inf_moy: chr "" "75.0" "70.0" "35.0" ...
## $ prof_inf_max: chr "" "" "" "" ...
## $ textur : chr "LA" "LMS" "LA" "LSA" ...
## $ abondance_eg: num 20 0 NA NA 30 20 NA 5 5 70 ...Nous pouvons décider que les valeurs manquantes du champ “abondance_eg” correspondent à des valeurs nulles (pas d’éléments grossiers). C’est une hypothèse forte.
Pour remplacer les NA par la valeur 0, il faut faire :
horizon$abondance_eg <- ifelse(is.na(horizon$abondance_eg), horizon$abondance_eg <-0, horizon$abondance_eg)
3.2 PREPARATION DES DONNEES D’ANALYSE GRANULOMETRIQUE SANS DECARBONATATION
3.2.1 II.1. Les seuils des fractions
Nous imposons que les seuils des fractions granulométriques et que la valeur soient bien en format numérique.
resultat_analyse_granulo$seuil_inferieur<-as.numeric(resultat_analyse_granulo$seuil_inferieur)
resultat_analyse_granulo$seuil_superieur<-as.numeric(resultat_analyse_granulo$seuil_superieur)
resultat_analyse_granulo$valeur<-as.numeric(resultat_analyse_granulo$valeur)Nous regardons les bornes des fractions présentes. Nous sortons pour cela un tableau du nombre d’occurences par seuil.
table(resultat_analyse_granulo$seuil_inferieur)##
## 0 2 20 50 100 200
## 9310 9310 9304 9310 16 9299
table(resultat_analyse_granulo$seuil_superieur)##
## 2 20 50 100 200 2000
## 9310 9304 9310 16 9310 9299Nous allons sommer les valeurs pour avoir le nombre de fractions souhaitées.
3.2.2 II.2. Regroupement en 3 fractions
Les 3 fractions sont :
- Argile 0-2 µm
- Limon 2-50 µm
- Sable 50-2000 µm
ⓘ NOTE
Vous pouvez aussi décider d’avoir 5 fractions au lieu de 3 en prenant 2 fractions pour le limon et 2 fractions pour le sable. Ici, nous avons décidé de prendre 3 fractions. Toutefois, une note dans les parties limon et sable, vous indique comment faire pour avoir 5 fractions.
3.2.2.1 II.2.1. Pour l’argile (0-2 µm)
Nous sélectionnons les données dont les seuils sont compris entre 0 et 2 µm.
library(magrittr)
A<- resultat_analyse_granulo %>%
filter(seuil_inferieur < 2, seuil_superieur < 2.1)
table(A$seuil_superieur)##
## 2
## 9310
table(A$seuil_inferieur)##
## 0
## 9310
colnames(A) # donne le nom des champs du fichier A## [1] "id_resultat" "id_ens_resultat_analyse_granulo"
## [3] "seuil_inferieur" "seuil_superieur"
## [5] "unite_seuil" "valeur"## id_resultat id_ens_resultat_analyse_granulo seuil_inferieur
## Min. : 12489 Min. : 2888 Min. :0
## 1st Qu.: 635854 1st Qu.:123450 1st Qu.:0
## Median : 790028 Median :153812 Median :0
## Mean : 715066 Mean :139277 Mean :0
## 3rd Qu.: 817768 3rd Qu.:159228 3rd Qu.:0
## Max. :1395493 Max. :271290 Max. :0
## seuil_superieur unite_seuil argile
## Min. :2 Length:9310 Min. : 5.3
## 1st Qu.:2 Class :character 1st Qu.:143.0
## Median :2 Mode :character Median :182.0
## Mean :2 Mean :204.0
## 3rd Qu.:2 3rd Qu.:238.0
## Max. :2 Max. :859.03.2.2.2 II.2.2. Pour le Limon (2-50 µm)
Pour le limon, nous avons plusieurs fractions dans DoneSol. Nous recherchons toutes les fractions comprises entre 2 et 50 µm et nous en faisons la somme par identifiant d’analyse granulo (champ id_ens_resultat_analyse_granulo).
L<- resultat_analyse_granulo %>%
filter(seuil_inferieur > 1.9, seuil_superieur < 50.1)
table(L$seuil_superieur)##
## 20 50
## 9304 9310
table(L$seuil_inferieur)##
## 2 20
## 9310 9304
# Somme par identifiant (champ id_ens_resultat_analyse_granulo)
L <- aggregate( valeur ~ id_ens_resultat_analyse_granulo, L, sum)
names(L)[names(L) == "valeur"] <- "limon" # renomme le champ valeur
summary(L)## id_ens_resultat_analyse_granulo limon
## Min. : 2888 Min. : 9
## 1st Qu.:123450 1st Qu.: 385
## Median :153812 Median : 508
## Mean :139277 Mean : 493
## 3rd Qu.:159228 3rd Qu.: 618
## Max. :271290 Max. :1033ⓘ NOTE
Pour obtenir 2 fractions pour les limons, vous devez prendre 2-20 µm pour les limons fins (Lf) et 20-50 µm pour les limons grossiers (Lg).
Le code R à réaliser est :
Lf<- resultat_analyse_granulo %>% filter(seuil_inferieur > 1.9, seuil_superieur < 20.1)
Lg<- resultat_analyse_granulo %>% filter(seuil_inferieur > 19.1, seuil_superieur < 50.1)
En fonction des données d’entrée, voir s’il est utile de faire une agrégation pour Lf et pour Lg.
3.2.2.3 II.2.3. Pour le sable (50-2000 µm)
Pour le sable, nous avons plusieurs fractions dans DoneSol. Nous recherchons toutes les fractions comprises entre 50 et 2000 µm et nous en faisons la somme par identifiant d’analyse granulo (champ id_ens_resultat_analyse_granulo).
S<- resultat_analyse_granulo %>%
filter(seuil_inferieur > 49.9, seuil_superieur < 2000.1)
table(S$seuil_superieur)##
## 100 200 2000
## 16 9310 9299
table(S$seuil_inferieur)##
## 50 100 200
## 9310 16 9299
# Somme par identifiant (champ id_ens_resultat_analyse_granulo)
S <- aggregate(valeur ~ id_ens_resultat_analyse_granulo, S, sum)
# library(plyr)
names(S)[names(S) == "valeur"] <- "sable" # renomme le champ valeur
summary(S)## id_ens_resultat_analyse_granulo sable
## Min. : 2888 Min. : 12.0
## 1st Qu.:123450 1st Qu.:172.0
## Median :153812 Median :266.0
## Mean :139277 Mean :301.2
## 3rd Qu.:159228 3rd Qu.:393.0
## Max. :271290 Max. :964.0ⓘ NOTE
Pour obtenir 2 fractions pour les sables, vous devez prendre 50-200 µm pour les sables fins (Sf) et 200-2000 µm pour les sables grossiers (Sg).
Le code R à réaliser pour le sable fin :
Sf<- resultat_analyse_granulo %>% filter(seuil_inferieur > 49.9, seuil_superieur < 200.1)
Sf <- aggregate(valeur ~ id_ens_resultat_analyse_granulo, Sf, sum)
Sf <- rename(Sf, c(“id_ens_resultat_analyse_granulo” = “id_ens_resultat_analyse_granulo”, “sable_fin” = “valeur”))
Le code R à réaliser pour le sable grossier :
Sg<- resultat_analyse_granulo %>% filter(seuil_inferieur > 199.9, seuil_superieur < 2000.1)
Sg <- aggregate(valeur ~ id_ens_resultat_analyse_granulo, Sg, sum)
Sg <- rename(Sg, c(“id_ens_resultat_analyse_granulo” = “id_ens_resultat_analyse_granulo”, >“sable_grossier” = “valeur”))
Nous compilons ensuite les 3 sommes argile + limon + sable dans un seul fichier (que nous avons appelé “granu”).
a<-full_join(A, L, by="id_ens_resultat_analyse_granulo")
granu<-full_join(a, S, by="id_ens_resultat_analyse_granulo")
rm(a) # supprime le dataframe intermédiaire
granu$somme <- (granu$argile + granu$limon + granu$sable) # rajoute un champ somme donnant la somme des 3 fractions
summary(granu)## id_resultat id_ens_resultat_analyse_granulo seuil_inferieur
## Min. : 12489 Min. : 2888 Min. :0
## 1st Qu.: 635854 1st Qu.:123450 1st Qu.:0
## Median : 790028 Median :153812 Median :0
## Mean : 715066 Mean :139277 Mean :0
## 3rd Qu.: 817768 3rd Qu.:159228 3rd Qu.:0
## Max. :1395493 Max. :271290 Max. :0
## seuil_superieur unite_seuil argile limon
## Min. :2 Length:9310 Min. : 5.3 Min. : 9
## 1st Qu.:2 Class :character 1st Qu.:143.0 1st Qu.: 385
## Median :2 Mode :character Median :182.0 Median : 508
## Mean :2 Mean :204.0 Mean : 493
## 3rd Qu.:2 3rd Qu.:238.0 3rd Qu.: 618
## Max. :2 Max. :859.0 Max. :1033
## sable somme
## Min. : 12.0 Min. : 100.0
## 1st Qu.:172.0 1st Qu.:1000.0
## Median :266.0 Median :1000.0
## Mean :301.2 Mean : 998.1
## 3rd Qu.:393.0 3rd Qu.:1000.0
## Max. :964.0 Max. :1400.03.2.3 II.3. Sélection de la granulométrie sans décarbonatation
Nous séparons les données sans décarbonatation de celles avec decarbonatation. Pour cela, nous utilisons la table PREPARATION_GRANULO qui donne le prétraitement de l’échantillon.
granulo<- full_join(granu, preparation_granulo, by="id_ens_resultat_analyse_granulo")
summary(granulo)## id_resultat id_ens_resultat_analyse_granulo seuil_inferieur
## Min. : 12489 Min. : 2888 Min. :0
## 1st Qu.: 635854 1st Qu.:123451 1st Qu.:0
## Median : 790028 Median :153812 Median :0
## Mean : 715066 Mean :139280 Mean :0
## 3rd Qu.: 817768 3rd Qu.:159227 3rd Qu.:0
## Max. :1395493 Max. :271290 Max. :0
## NA's :2 NA's :2
## seuil_superieur unite_seuil argile limon
## Min. :2 Length:9312 Min. : 5.3 Min. : 9
## 1st Qu.:2 Class :character 1st Qu.:143.0 1st Qu.: 385
## Median :2 Mode :character Median :182.0 Median : 508
## Mean :2 Mean :204.0 Mean : 493
## 3rd Qu.:2 3rd Qu.:238.0 3rd Qu.: 618
## Max. :2 Max. :859.0 Max. :1033
## NA's :2 NA's :2 NA's :2
## sable somme id_preparation_granulo pretrait_d2
## Min. : 12.0 Min. : 100.0 Min. : 22516 Min. :2.000
## 1st Qu.:172.0 1st Qu.:1000.0 1st Qu.: 69229 1st Qu.:9.000
## Median :266.0 Median :1000.0 Median : 72577 Median :9.000
## Mean :301.2 Mean : 998.1 Mean : 74120 Mean :8.142
## 3rd Qu.:393.0 3rd Qu.:1000.0 3rd Qu.: 78765 3rd Qu.:9.000
## Max. :964.0 Max. :1400.0 Max. :185249 Max. :9.000
## NA's :2 NA's :2 NA's :3384 NA's :9058
## pretrait_d3 peptis
## Min. :9 Mode:logical
## 1st Qu.:9 NA's:9312
## Median :9
## Mean :9
## 3rd Qu.:9
## Max. :9
## NA's :5679
granulo$traitement <- ifelse(granulo$pretrait_d2 ==1 | granulo$pretrait_d2 ==3 | granulo$pretrait_d2 ==6 |
granulo$pretrait_d2 ==8 | granulo$pretrait_d3 ==1 |
granulo$pretrait_d3 ==3 | granulo$pretrait_d3 ==6 |
granulo$pretrait_d3 ==8, "decarb", "no_decarb") # indique le prétraitement si connu
granu_decarb <- subset(granulo, traitement == "decarb") # analyses granulo après décarbonatation
granu_no_decarb <- setdiff(granulo, granu_decarb) # analyses granulo sans décarbonatationAu final, notre fichier “granu_decarb” contient les granulométries décarbonatées en 3 fractions et notre fichier “granu_no_decarb” contient les granulométries non décarbonatées en 3 fractions. Nos teneurs en argile, limon et sable sont en g/kg. Par la suite, nous utiliserons les granulométries non décarbonatées.
Nous rapatrions les identifiants des tables PROFIL et HORIZON.
id <- full_join(analyse, ens_resultat_analyse_granulo, by="id_analyse")
id <- data.frame("id_analyse"=id$id_analyse, "id_prelevement"=id$id_prelevement,
"id_profil"=id$id_profil, "no_horizon"=id$no_horizon,
"id_ens_resultat_analyse_granulo"=id$id_ens_resultat_analyse_granulo)
granulo_no_decarb <- left_join(granu_no_decarb, id, by="id_ens_resultat_analyse_granulo")
granulo_decarb <- left_join(granu_decarb, id, by="id_ens_resultat_analyse_granulo")
summary(granulo_no_decarb)## id_resultat id_ens_resultat_analyse_granulo seuil_inferieur
## Min. : 12489 Min. : 2888 Min. :0
## 1st Qu.: 635853 1st Qu.:123450 1st Qu.:0
## Median : 790018 Median :153810 Median :0
## Mean : 715056 Mean :139278 Mean :0
## 3rd Qu.: 817769 3rd Qu.:159228 3rd Qu.:0
## Max. :1395493 Max. :271290 Max. :0
## NA's :2 NA's :2
## seuil_superieur unite_seuil argile limon
## Min. :2 Length:9311 Min. : 5.3 Min. : 9
## 1st Qu.:2 Class :character 1st Qu.:143.0 1st Qu.: 385
## Median :2 Mode :character Median :182.0 Median : 508
## Mean :2 Mean :204.0 Mean : 493
## 3rd Qu.:2 3rd Qu.:238.0 3rd Qu.: 618
## Max. :2 Max. :859.0 Max. :1033
## NA's :2 NA's :2 NA's :2
## sable somme id_preparation_granulo pretrait_d2
## Min. : 12.0 Min. : 100.0 Min. : 22516 Min. :2.000
## 1st Qu.:172.0 1st Qu.:1000.0 1st Qu.: 69228 1st Qu.:9.000
## Median :266.0 Median :1000.0 Median : 72576 Median :9.000
## Mean :301.2 Mean : 998.1 Mean : 74120 Mean :8.142
## 3rd Qu.:393.0 3rd Qu.:1000.0 3rd Qu.: 78766 3rd Qu.:9.000
## Max. :964.0 Max. :1400.0 Max. :185249 Max. :9.000
## NA's :2 NA's :2 NA's :3384 NA's :9058
## pretrait_d3 peptis traitement id_analyse
## Min. :9 Mode:logical Length:9311 Min. : 2925
## 1st Qu.:9 NA's:9311 Class :character 1st Qu.:122774
## Median :9 Mode :character Median :136138
## Mean :9 Mean :138666
## 3rd Qu.:9 3rd Qu.:173300
## Max. :9 Max. :249765
## NA's :5678
## id_prelevement id_profil no_horizon
## Min. : 2922 Min. : 382 Min. :1.000
## 1st Qu.:111499 1st Qu.: 84580 1st Qu.:1.000
## Median :149622 Median : 90455 Median :2.000
## Mean :140618 Mean : 93677 Mean :2.271
## 3rd Qu.:204398 3rd Qu.:126116 3rd Qu.:3.000
## Max. :272719 Max. :139441 Max. :6.000
## NA's :600Nous vérifions que la somme des 3 fractions = 1000 pour la granulométrie sans décarbonatation (fichier “granulo_no_decarb”). Nous supprimons les valeurs inférieures à 800 g/kg et supérieures à 1200 g/kg. A l’intérieur de cet intervale, nous considérons qu’il s’agit de l’erreur d’analyse car les anciennes données n’étaient pas fournies par le laboratoire avec une somme exactement égale à 1000 g/kg (ou 100%).
granulo_no_decarb<-granulo_no_decarb %>% filter(!is.na(id_profil)) # suppression des enregistrements sans id_profil
granulo_no_decarb<-granulo_no_decarb %>% filter(!is.na(somme)) # suppression des enregistrements sans granulo
granulo_no_decarb<-filter(granulo_no_decarb, somme > 800, somme < 1200) # filtre sur la somme de la granulo
# si la somme des granulo est différente de 1000, nous faisons une règle de 3 pour que la somme fasse 1000
# rajout de champs A, L et S corrigés
granulo_no_decarb$argile_cor<-((granulo_no_decarb$argile/granulo_no_decarb$somme)*1000)
granulo_no_decarb$limon_cor<-((granulo_no_decarb$limon/granulo_no_decarb$somme)*1000)
granulo_no_decarb$sable_cor<-((granulo_no_decarb$sable/granulo_no_decarb$somme)*1000)
granulo_no_decarb$somme_cor <- (granulo_no_decarb$argile_cor + granulo_no_decarb$limon_cor + granulo_no_decarb$sable_cor)
summary(granulo_no_decarb$somme_cor)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 1000 1000 1000 1000 1000 1000
# Choix des variables à conserver dans le fichier GRANULO_NO_DECARB
granulo_no_decarb<-data.frame("id_ens_resultat_analyse_granulo"=granulo_no_decarb$id_ens_resultat_analyse_granulo,
"id_analyse"=granulo_no_decarb$id_analyse,
"id_prelevement"=granulo_no_decarb$id_prelevement,
"id_profil"=granulo_no_decarb$id_profil,
"no_horizon"=granulo_no_decarb$no_horizon,
"argile"=granulo_no_decarb$argile_cor,
"limon"=granulo_no_decarb$limon_cor,
"sable"=granulo_no_decarb$sable_cor)
summary(granulo_no_decarb)## id_ens_resultat_analyse_granulo id_analyse id_prelevement
## Min. : 2888 Min. : 2925 Min. : 2922
## 1st Qu.:123451 1st Qu.:122765 1st Qu.:111499
## Median :153808 Median :136138 Median :149628
## Mean :139274 Mean :138673 Mean :140680
## 3rd Qu.:159224 3rd Qu.:173306 3rd Qu.:204407
## Max. :271290 Max. :249765 Max. :272719
## NA's :599
## id_profil no_horizon argile limon
## Min. : 382 Min. :1.000 Min. : 9.793 Min. : 9.0
## 1st Qu.: 84574 1st Qu.:1.000 1st Qu.:144.000 1st Qu.:387.0
## Median : 90455 Median :2.000 Median :182.182 Median :509.5
## Mean : 93685 Mean :2.271 Mean :204.316 Mean :493.9
## 3rd Qu.:126116 3rd Qu.:3.000 3rd Qu.:238.940 3rd Qu.:619.0
## Max. :139441 Max. :6.000 Max. :858.142 Max. :871.0
##
## sable
## Min. : 11.99
## 1st Qu.:172.00
## Median :266.40
## Mean :301.77
## 3rd Qu.:393.00
## Max. :964.96
## Par la suite, nous utiliserons les champs corrigés : argile_cor, limon_cor et sable_cor en g/kg de notre nouvelle table granulo_no_decarb.
Nous pouvons donc supprimer les tables devenues inutiles :
rm(granu) # suppression de la table GRANU
rm(resultat_analyse_granulo)# suppression de la table RESULTAT_ANALYSE_GRANULO
rm(ens_resultat_analyse_granulo)# suppression de la table ENS_RESULTAT_ANALYSE_GRANULO
rm(preparation_granulo)# suppression de la table PREPARATION_GRANULO
rm(granulo_decarb) # suppression de la table GRANULO_DECARB
rm(A) # suppression de la table A
rm(L) # suppression de la table L
rm(S) # suppression de la table S
rm(id) # suppression de la table id
rm(granu_decarb) # supression de la table GRANU_DECARB
rm(granu_no_decarb) # supression de la table GRANU_NO_DECARB
rm(granulo) # supression de la table GRANULO3.2.4 II.4. Option : projection des valeurs de granulométrie dans un triangle de texture
Pour visualiser les valeurs de granulométrie dans un triangle de texture, nous utiliserons le package SoilTexture (https://cran.r-project.org/web/packages/soiltexture/vignettes/soiltexture_vignette.pdf). Pour projeter les valeurs de granulométrie, celles-ci doivent être en % et non en g/kg. Nous devons aussi renommer les variables en anglais avec CLAY pour l’argile, SILT pour le limon et SAND pour le sable. La somme des 3 fractions doit absolument boucler à 100%.
# Nous mettons les fractions en % et les renommons en CLAY, SILT, SAND
texture <- data.frame("CLAY"=granulo_no_decarb$argile/10, "SILT"=granulo_no_decarb$limon/10, "SAND" = granulo_no_decarb$sable/10)
# Projection dans le triangle de texture de l'Aisne
TT.plot(
class.sys = "FR.AISNE.TT", # choix du triangle de texture
tri.data = texture, # localisation des données
grid.show = FALSE, # effacer la grille de fond du triangle
new.mar = c(2,0,4,0), # marges du graphique
lwd.axis = 2, cex.axis=0.7, # épaisseur des lignes et taille du texte des axes
col = "blue", pch=20, cex = 0.0001, # couleur, forme et taille des points
cex.lab = 0.8, css.lab = c( "argile [%]", "limon [%]", "sable [%]" ), # label des cotés du triangle
main = "Triangle de l'Aisne" # titre de la figure
)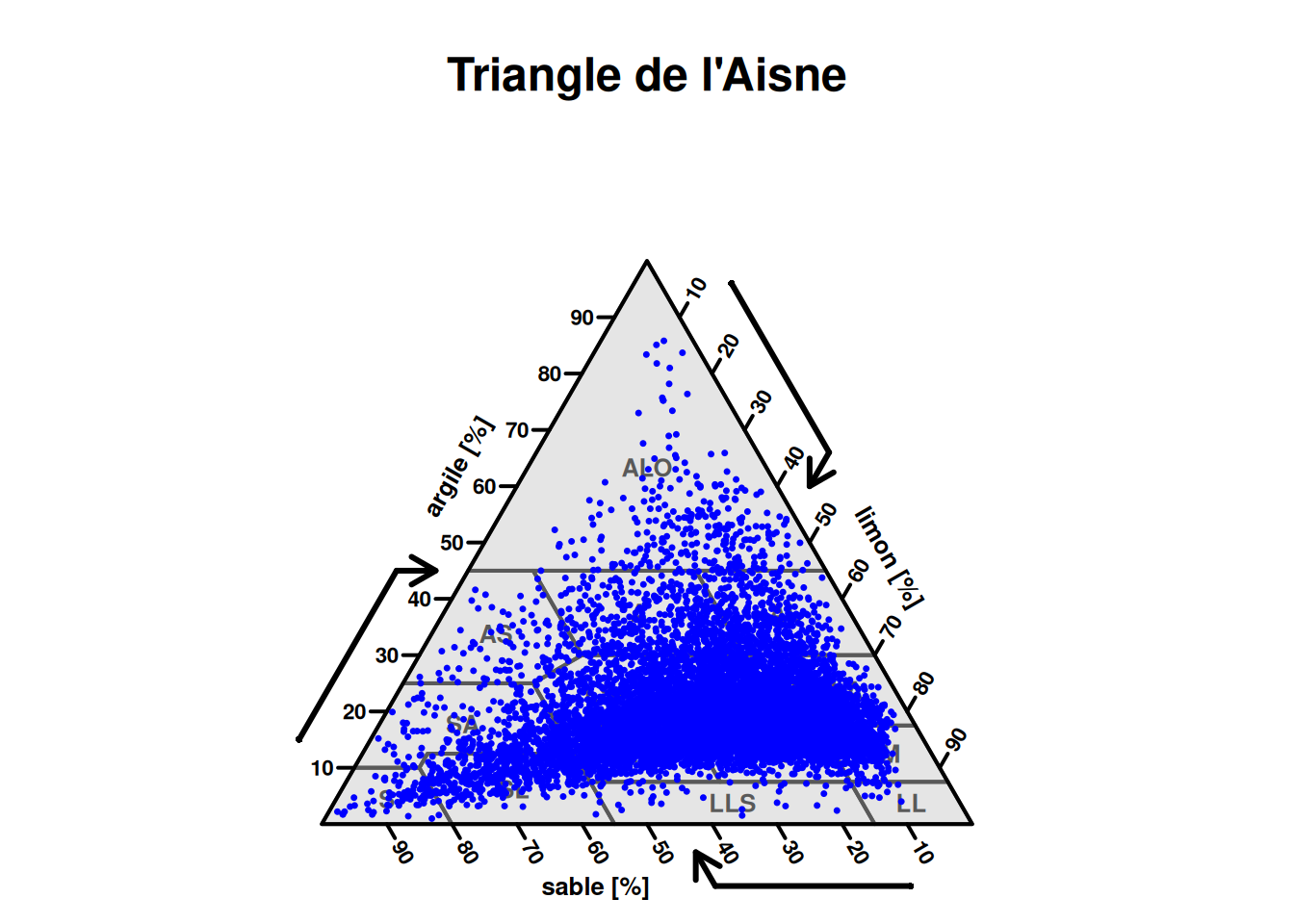
rm(texture) # suppression du fichier TEXTURE qui ne sera plus utile par la suiteIl s’agit ici de toutes les granulométries sans décarbonatation tout horizons confondus.
3.3 PREPARATION DES DONNEES D’ANALYSES CHIMIQUES
Pour ces données, nous devons faire particulièrement attention aux méthodes d’analyse et aux unités. Les données d’analyses chimiques sont stockées dans la table RESULTAT_ANALYSE de DoneSol. Attention : dans le dictionnaire de données, ce sont les numéros de méthode (no_methode) qui sont indiquées, alors que dans les tables nous trouvons les identifiants des méthodes (id_methode). Le fichier “id_methode.xlsx” contient la correspondance.
Attention à ne pas confondre le champ NO_METHODE qui correspond au code indiqué dans les tableaux de la table RESULTAT_ANALYSE du dictionnaire de données et le champ ID_METHODE qui est l’identifiant de la méthode d’analyse dans DoneSol. Il existe bien sûr une correspondance entre les deux (fichier “id_methode.xlsx”).
# importation des méthodes
methods <- read_xlsx("donnees/jour1/id_methode.xlsx") %>%
mutate(id_method = as.character(id_method) )3.3.1 III.1. Carbone organique total (g/kg)
Nous chargeons les données d’analyse du carbone avec l’identifiant de la méthode. Pour le carbone, la méthode d’analyse est importante et il est nécessaire de choisir les méthodes retenues.
carbone<- resultat_analyse %>%
filter(determination == 'carbone') %>%
select(id_resultat, id_analyse,id_methode,valeur)%>%
rename(id_methode_carbone = id_methode,
carbone = valeur)Il peut arriver que le carbone ne soit pas renseigné dans DoneSol mais que la détermination MAT_ORG (matière organique) le soit. Il est alors possible de compléter la détermination CARBONE à partir de la détermination MAT_ORG en appliquant CARBONE = MAT_ORG / 1.724.
mat_org<-subset(resultat_analyse, determination == 'mat_org')
mat_org<-data.frame("id_resultat"=mat_org$id_resultat,
"id_analyse"=mat_org$id_analyse,
"id_methode_mat_org"=mat_org$id_methode,
"mat_org"=mat_org$valeur)
## On complete carbone avec mat_org dans une nouvelle table CARBONE2
# jointure entière entre carbone et mat_org
carbone2<- full_join(carbone, mat_org, by="id_analyse")
# supression des doublons
carbone2<-distinct(carbone2, .keep_all = FALSE)
# on rajoute un champ carb_calc contenant une valeur de carbone calculée à partir de mat_org
carbone2$mat_org<-as.numeric(carbone2$mat_org) # mise en numérique du champ mat_org
carbone2$carbone<-as.numeric(carbone2$carbone) # mise en numérique du champ valeur
carbone2$carb_calc <- (carbone2$mat_org / 1.724)
# on complète carbone avec cette valeur calculée
carbone2$carbone <- ifelse(!is.na(carbone2$carbone),
carbone2$carbone,
carbone2$carb_calc)Pour le carbone, nous allons séparer les données selon les méthodes d’analyse. Nous allons créer un fichier contenant le carbone analysé selon la méthode Anne et un fichier contenant le carbone analysé par combustion sèche (CS).
carbone2$id_methode_carbone<-as.character(carbone2$id_methode_carbone)
carbone2<- left_join(carbone2,
methods,
by=c("id_methode_carbone"="id_method"))
# choix des méthodes de DoneSol correspondant à la méthode Anne
carbone_anne<-subset(carbone2, no_methode %in% c("1","17", "17.1", "17.2", "17.3", "17.4", "17.5",
"17.6", "17.7", "17.8", "17.9","17.10",
"17.10.1","17.10.2", "17.10.3","17.11", "120"))
colnames(carbone_anne)[4] <- c("carbone_anne") # renommer la colonne
carbone_anne$id_analyse <- as.numeric (carbone_anne$id_analyse) # Mettre le résultat en numérique. Il est toujours en g/kg.
carbone_anne<-data.frame("id_analyse"=carbone_anne$id_analyse,
"carbone_anne"=carbone_anne$carbone_anne)
summary(carbone_anne)## id_analyse carbone_anne
## Min. : 2925 Min. : 0.70
## 1st Qu.:122255 1st Qu.: 12.90
## Median :162857 Median : 17.00
## Mean :138284 Mean : 19.09
## 3rd Qu.:173582 3rd Qu.: 22.10
## Max. :188403 Max. :443.00
# choix des méthodes de DoneSol correspondant à la combustion sèche
carbone_cs<-subset(carbone2, no_methode %in% c("16", "16.1", "16.2", "16.2.1", "16.2.2", "16.3",
"16.4", "16.5", "16.5.1", "16.5.2"))
colnames(carbone_cs)[4] <- c("carbone_cs") # renommer la colonne
carbone_cs$id_analyse <- as.numeric (carbone_cs$id_analyse) # Mettre le résultat en numérique. Il est toujours en g/kg.
carbone_cs<-data.frame("id_analyse"=carbone_cs$id_analyse,
"carbone_cs"=carbone_cs$carbone_cs)
summary(carbone_cs)## id_analyse carbone_cs
## Min. :122961 Min. :12.00
## 1st Qu.:127254 1st Qu.:14.40
## Median :127327 Median :19.00
## Mean :135856 Mean :18.66
## 3rd Qu.:127598 3rd Qu.:21.80
## Max. :174139 Max. :26.10Nous avons ainsi des résultats d’analyse propre pour le carbone. Nous pouvons les visualiser avec un histogramme avec la fonction hist() Sa syntaxe de base est : hist(x, breaks = “…”, col = “la couleur”, main = “le titre”, xlab = “Valeurs”, ylab = “Fréquence”…) Voici un exemple pour le carbone méthode Anne :
hist(carbone_anne$carbone_anne,
breaks= 100,
col="darkgoldenrod1",
main="Histogramme du carbone Anne",
xlab = "carbone (g/kg)")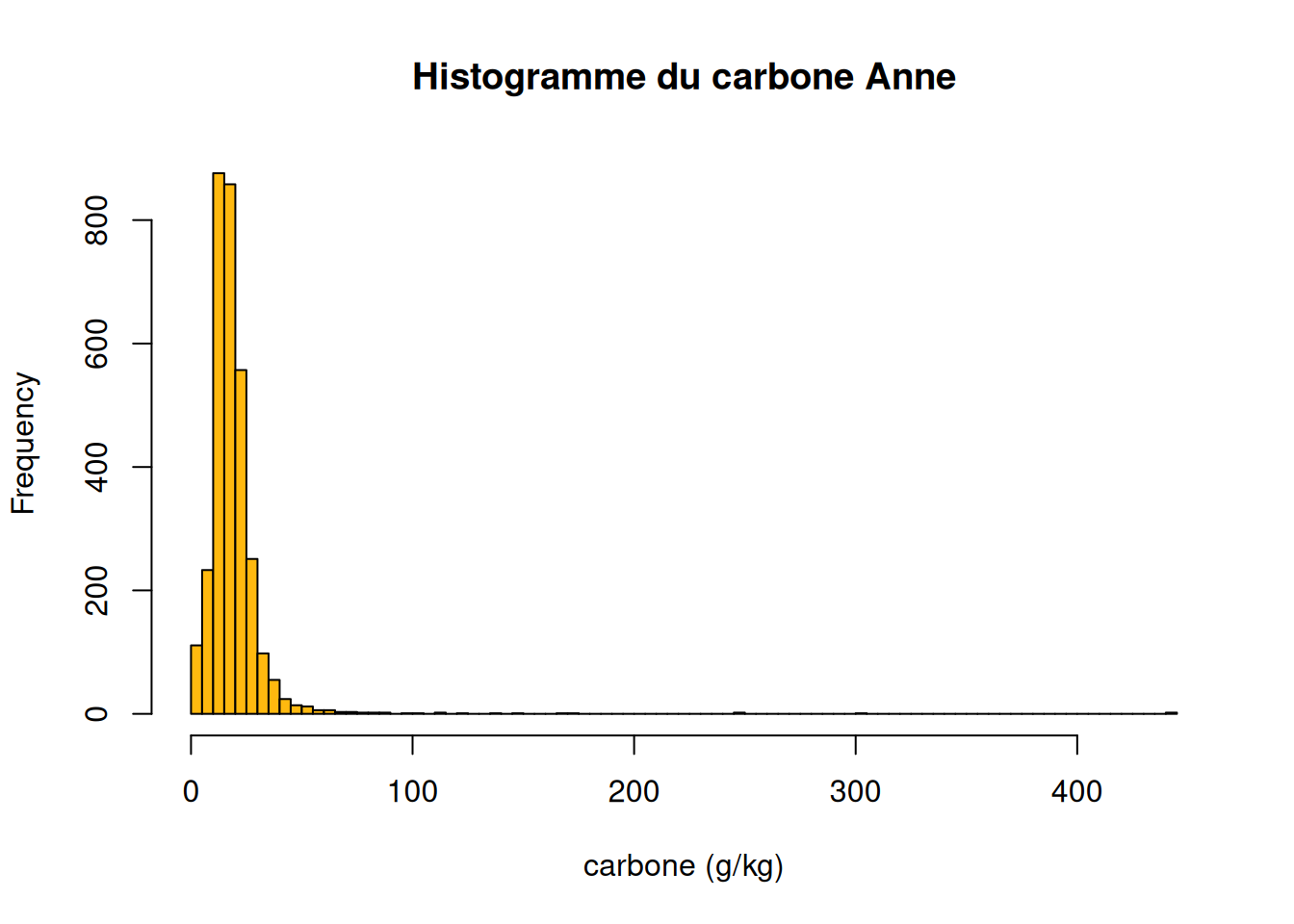
Nous supprimons les fichiers devenus inutiles
3.3.2 III.2. pH eau (unité pH)
# Import pH eau
ph_eau<-subset(resultat_analyse, determination == 'ph_eau')
ph_eau<-data.frame("id_resultat"=ph_eau$id_resultat,
"id_analyse"=ph_eau$id_analyse,
"id_methode_ph_eau"=ph_eau$id_methode,
"ph_eau"=ph_eau$valeur)
ph_eau$ph_eau<- as.numeric(ph_eau$ph_eau)Nous réalisons l’histogramme du pH eau :
hist(ph_eau$ph_eau, breaks= 25, xlim=c(3,10), col="tomato", main="Histogramme du pHeau", xlab = "pH eau")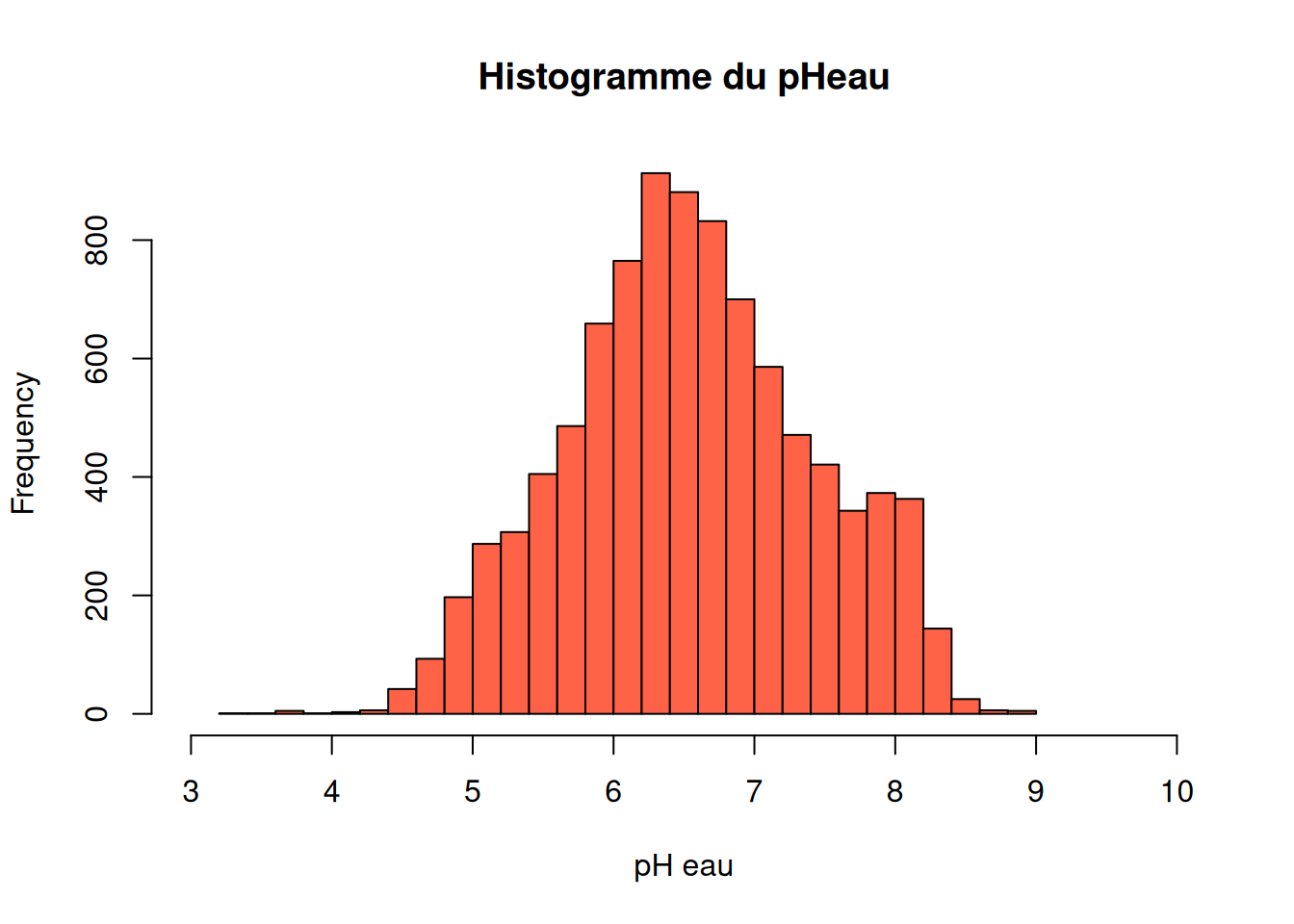
3.3.3 III.3. CEC (mé/100g)
# Import cec
cec<-subset(resultat_analyse, determination == 'cec')
cec<-data.frame("id_resultat"=cec$id_resultat,
"id_analyse"=cec$id_analyse,
"id_methode_cec"=cec$id_methode,
"cec"=cec$valeur)Pour la CEC, la méthode d’analyse est importante. Nous allons séparer la méthode Metson et la méthode à la cobaltihexammine.
## Pour la CEC
cec$id_methode_cec <- as.character(cec$id_methode_cec)
cec<- dplyr::left_join(cec, methods, by=c("id_methode_cec"="id_method"))
# Sélection de la méthode Metson
cec_metson<-subset(cec, no_methode %in% c("41", "41.4", "41.5", "41.5.1", "41.5.2", "41.6", "41.6.1", "41.7", "41.8", "41.9"))
colnames(cec_metson)[4] <- c("cec_metson")
cec_metson$cec_metson<-as.numeric(cec_metson$cec_metson)
summary(cec_metson$cec_metson) # synthèse de la cec metson## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.500 6.100 7.800 8.344 9.700 150.000
# Sélection de la méthode à la cobaltihexammine
cec_cobalti<-subset(cec, no_methode %in% c("40", "40.1", "40.1.1", "40.2", "40.2.2", "40.5"))
colnames(cec_cobalti)[4] <- c("cec_cobalti")
cec_cobalti$cec_cobalti<-as.numeric(cec_cobalti$cec_cobalti)
# Supression du fichier cec devenu inutile
rm(cec)
# Exploration des données
summary(cec_cobalti$cec_cobalti)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.900 5.700 7.500 7.926 9.400 30.5003.3.4 III.4. Calcaire total (calc_tot CaCO3 en g/kg)
# Importation de la détermination calc_tot
calc_tot<-subset(resultat_analyse, determination == 'calc_tot')
calc_tot<-data.frame("id_resultat"=calc_tot$id_resultat,
"id_analyse"=calc_tot$id_analyse,
"id_methode_calc_tot"=calc_tot$id_methode,
"calc_tot"=calc_tot$valeur)
calc_tot$calc_tot <- as.numeric(calc_tot$calc_tot)
summary(calc_tot)## id_resultat id_analyse id_methode_calc_tot calc_tot
## Min. : 413703 Min. :52975 Min. :1.000 Min. : 0.000
## 1st Qu.: 415262 1st Qu.:53076 1st Qu.:1.000 1st Qu.: 0.100
## Median : 415321 Median :53175 Median :1.000 Median : 0.400
## Mean :1068654 Mean :53826 Mean :1.526 Mean : 1.995
## 3rd Qu.:1924489 3rd Qu.:54512 3rd Qu.:1.000 3rd Qu.: 1.650
## Max. :2096270 Max. :55846 Max. :6.000 Max. :10.500ⓘ NOTE
Vous pouvez sur le même modèle charger d’autres déterminations de la table RESULTAT_ANALYSE.
3.4 FUSION DES DONNEES DANS UN SEUL FICHIER
Nous allons regrouper l’ensemble de nos informations extraites et préparées précédemment dans un seul fichier. Cela sera ensuite plus facile à utiliser. Nous allons appeler ce fichier un datamart car il regroupe des informations de différentes tables de DoneSol.
Pour cela, nous utilisons des jointures entre les tables.
dm_sol<-full_join(profil,poi, by="id_profil") # jointure entre PROFIL et POI
dm_sol<-left_join(dm_sol,horizon, by="id_profil") # jointure entre DM_SOL et HORIZON
dm_sol<-left_join(dm_sol, granulo_no_decarb, by=c("id_profil", "no_horizon")) # jointure entre DM_SOL et GRANULO_NO_DECARB## Warning in left_join(dm_sol, granulo_no_decarb, by = c("id_profil", "no_horizon")): Detected an unexpected many-to-many relationship between `x` and `y`.
## ℹ Row 241 of `x` matches multiple rows in `y`.
## ℹ Row 1686 of `y` matches multiple rows in `x`.
## ℹ If a many-to-many relationship is expected, set `relationship =
## "many-to-many"` to silence this warning.
dm_sol<-left_join(dm_sol, carbone_anne, by= "id_analyse") # jointure entre DM_SOL et CARBONE_ANNE## Warning in left_join(dm_sol, carbone_anne, by = "id_analyse"): Detected an unexpected many-to-many relationship between `x` and `y`.
## ℹ Row 5626 of `x` matches multiple rows in `y`.
## ℹ Row 938 of `y` matches multiple rows in `x`.
## ℹ If a many-to-many relationship is expected, set `relationship =
## "many-to-many"` to silence this warning.
dm_sol<-left_join(dm_sol, calc_tot, by= "id_analyse") # jointure entre DM_SOL et CALC_TOT
dm_sol<-left_join(dm_sol, cec_cobalti, by= "id_analyse") # jointure entre DM_SOL et CEC_COBALTI
dm_sol<-left_join(dm_sol, cec_metson, by= "id_analyse") # jointure entre DM_SOL et CEC_METSON
dm_sol<-left_join(dm_sol, ph_eau, by= "id_analyse") # jointure entre DM_SOL et PH_EAU
dm_sol<-left_join(dm_sol, analyse, by= "id_analyse", copy=FALSE) # jointure entre DM_SOL et ANALYSENous allons ensuite simplifier ce fichier pour ne conserver que les champs utiles pour la suite.
# Nous supprimons les champs inutiles car redondants
names(dm_sol) # Nous donne le numéro de colonne de tous les champs de la table dm_sol. ## [1] "id_profil.x" "altitude"
## [3] "date_p" "drai_nat_p"
## [5] "arret" "prof_arret"
## [7] "landuse" "GER"
## [9] "x_l93" "y_l93"
## [11] "no_horizon.x" "cpcs_nom"
## [13] "rp_95_nom" "rp_2008_nom"
## [15] "prof_sup_min" "prof_sup_moy"
## [17] "prof_sup_max" "prof_inf_min"
## [19] "prof_inf_moy" "prof_inf_max"
## [21] "textur" "abondance_eg"
## [23] "id_ens_resultat_analyse_granulo" "id_analyse"
## [25] "id_prelevement.x" "argile"
## [27] "limon" "sable"
## [29] "carbone_anne" "id_resultat.x"
## [31] "id_methode_calc_tot" "calc_tot"
## [33] "id_resultat.y" "id_methode_cec.x"
## [35] "cec_cobalti" "no_methode.x"
## [37] "name_method.x" "id_resultat.x.x"
## [39] "id_methode_cec.y" "cec_metson"
## [41] "no_methode.y" "name_method.y"
## [43] "id_resultat.y.y" "id_methode_ph_eau"
## [45] "ph_eau" "id_profil.y"
## [47] "no_horizon.y" "id_prelevement.y"
## [49] "prof_base" "prof_sommet"
# Cela nous permet de sélectionner les champs à supprimer.
# Nous supprimons les champs que nous ne souhaitons pas conserver.
dm_sol <- dm_sol[,-c(33, 34,38, 39, 41,42, 43, 44, 46, 47, 48)]
# Renommer les champs
names(dm_sol)[names(dm_sol) == "id_profil.x"] <- "id_profil"
names(dm_sol)[names(dm_sol) == "no_horizon.x"] <- "no_horizon"
names(dm_sol)[names(dm_sol) == "id_prelevement.x"] <- "id_prelevement"
names(dm_sol)[names(dm_sol) == "id_resultat.x"] <- "id_resultat"
names(dm_sol)[names(dm_sol) == "no_methode.x"] <- "no_methode"
names(dm_sol)[names(dm_sol) == "name_method.x"] <- "name_method"
# On remet les champs qui doivent y être en numérique
dm_sol$cec_cobalti<-as.numeric(dm_sol$cec_cobalti)
dm_sol$cec_metson<-as.numeric(dm_sol$cec_metson)
dm_sol$prof_sup_min<-as.numeric(dm_sol$prof_sup_min)
dm_sol$prof_sup_moy<-as.numeric(dm_sol$prof_sup_moy)
dm_sol$prof_sup_max<-as.numeric(dm_sol$prof_sup_max)
dm_sol$prof_inf_min<-as.numeric(dm_sol$prof_inf_min)
dm_sol$prof_inf_moy<-as.numeric(dm_sol$prof_inf_moy)
dm_sol$prof_inf_max<-as.numeric(dm_sol$prof_inf_max)
str(dm_sol)## 'data.frame': 10334 obs. of 39 variables:
## $ id_profil : int 110185 110185 110185 132400 132400 132400 96907 96907 96907 84414 ...
## $ altitude : chr "" "" "" "" ...
## $ date_p : chr "01/10/1975" "01/10/1975" "01/10/1975" "15/04/1990" ...
## $ drai_nat_p : int NA NA NA NA NA NA NA NA NA NA ...
## $ arret : int 1 1 1 2 2 2 1 1 1 1 ...
## $ prof_arret : int NA NA NA NA NA NA NA NA NA NA ...
## $ landuse : Factor w/ 7 levels "Forets","Prairies_permanentes",..: 2 2 2 3 3 3 3 3 3 3 ...
## $ GER : Factor w/ 34 levels "ALOCRISOL","ALOCRISOL-REDOXISOL",..: 4 4 4 4 4 4 4 4 4 12 ...
## $ x_l93 : num 397918 397918 397918 472986 472986 ...
## $ y_l93 : num 6751603 6751603 6751603 6820284 6820284 ...
## $ no_horizon : int 1 3 2 2 1 3 2 1 3 1 ...
## $ cpcs_nom : chr "Ap" "C" "B" "" ...
## $ rp_95_nom : chr "" "" "" "Sg" ...
## $ rp_2008_nom : chr "" "" "" "" ...
## $ prof_sup_min : num NA NA NA NA NA NA NA NA NA NA ...
## $ prof_sup_moy : num 0 50 25 25 0 40 20 0 80 0 ...
## $ prof_sup_max : num NA NA NA NA NA NA NA NA NA NA ...
## $ prof_inf_min : num NA NA NA NA NA NA NA NA NA NA ...
## $ prof_inf_moy : num 25 60 50 40 25 130 80 20 120 20 ...
## $ prof_inf_max : num NA NA NA NA NA NA NA NA NA NA ...
## $ textur : chr "LSa" "ND" "LAS" "SL" ...
## $ abondance_eg : num 20 NA 70 60 30 60 70 20 65 10 ...
## $ id_ens_resultat_analyse_granulo: int 2936 NA 2937 124783 124782 124784 102543 102542 102544 101847 ...
## $ id_analyse : num 2981 NA 2982 165346 165345 ...
## $ id_prelevement : int 2978 NA 2979 151194 151193 151195 115273 115272 115274 114602 ...
## $ argile : num 188 NA 225 173 170 ...
## $ limon : num 542 NA 463 461 384 ...
## $ sable : num 270 NA 312 366 446 ...
## $ carbone_anne : num 18.4 NA NA NA 28.5 NA NA 33 NA 27 ...
## $ id_resultat : int NA NA NA NA NA NA NA NA NA NA ...
## $ id_methode_calc_tot : int NA NA NA NA NA NA NA NA NA NA ...
## $ calc_tot : num NA NA NA NA NA NA NA NA NA NA ...
## $ cec_cobalti : num NA NA NA NA NA NA NA NA NA NA ...
## $ no_methode : chr NA NA NA NA ...
## $ name_method : chr NA NA NA NA ...
## $ cec_metson : num NA NA NA 7.4 8 3.4 14 13 10.7 13.1 ...
## $ ph_eau : num 5.6 NA 6.3 6 5.8 5.6 7.5 6.6 5.8 4.8 ...
## $ prof_base : num 25 45 50 40 25 130 80 20 100 20 ...
## $ prof_sommet : num 0 30 25 25 0 40 25 0 80 0 ...Nous vérifions que nos données n’ont pas changées et que nous retrouvons bien dans dm_sol nos données d’origine. Pour cela, nous pouvons par exemple refaire l’histogramme du pH à partir de dm_sol.
par(mfrow = c(1, 2)) # séparation de la page en 2 colonnes
# Histogramme à partir de la table ph_eau
hist(ph_eau$ph_eau,
breaks= 25,
xlim=c(3,10),
col="tomato",
main="Histogramme du pHeau (ph_eau)",
xlab = "pH eau")
# histogramme à partir de la table dm_sol
hist(dm_sol$ph_eau,
breaks= 25,
xlim=c(3,10),
col="tomato",
main="Histogramme du pHeau (dm_sol)",
xlab = "pH eau")
Les 2 histogrammes doivent être identiques.
Il est possible de sauvegarder le fichier final en CSV :
# write.csv2(dm_sol, file = "dm_sol.csv")
# Nous supprimons alors l'ensemble des tables et ne conservons que le fichier dm_sol.
rm(analyse)
rm(calc_tot)
rm(carbone_anne)
rm(carbone_cs)
rm(cec_cobalti)
rm(cec_metson)
rm(granulo_no_decarb)
rm(horizon)
rm(ph_eau)
rm(profil)
rm(resultat_analyse)
rm(resultat_eg)3.5 SELECTION DE COUCHES DE PROFONDEURS AVEC DES SPLINES
Ici nous allons faire une modélisation de la profondeur en utilisant un algorithme d’ajustement quadratique fondé sur des surfaces égales [souvent résumée par le mot « spline » (Bishop et al., 1999 ; Malone et al., 2009)]. Cette fonction est fondée sur des ajustements polynômiaux et lisse les données sur l’ensemble de la profondeur du sol. Elle impose une contrainte qui est que la courbe ajustée sur les horizons d’origine et passant par leur profondeur moyenne respecte pour chaque horizon des surfaces égales pour les aires comprises entre cette courbe et une droite verticale passant par les valeurs moyennes affectées aux horizons.
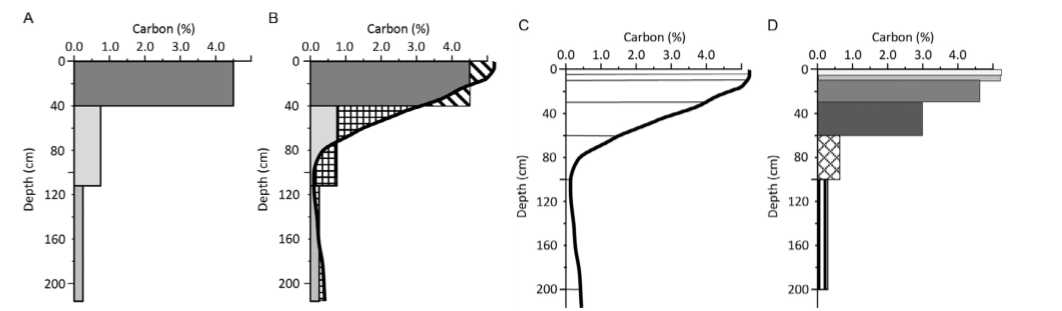
Schématisation du principe d’ajustement d’une fonction polynomiale quadratique (« spline ») à partir d’observations supposées représenter une valeur moyenne d’une propriété mesurée sur des horizons parallèles (rectangles verticaux en A) en respectant, par horizon, des surfaces de valeurs inférieures ou supérieures égales à la moyenne de cet horizon (surfaces hachurées en B), pour obtenir un « spline » (en C), puis utiliser le « spline » pour inférer des valeurs par couches GlobalSoilMap standardisées (en D). Exemple sur le carbone, extrait de (Arrouays et al., 2014), et lui-même adapté de Bishop et al. (1999) et Malone et al. (2009).
Liste des références
Arrouays, D., Grundy, M. G., Hartemink, A., Hempel, J., Heuvelink, G., Hong, S., Lagacherie, P., Lelyk, G., McBratney, A., McKenzie, N., Mendonca-Santos, M., Minasny, B., Montanarella, L., Odeh, I., Sanchez, P., Thompson, J. et Zhang, G. (2014a). GlobalSoilMap: Toward a Fine-Resolution Global Grid of Soil Properties. Dans D. Sparks (dir.), Advances in Agronomy (vol. 125, p. 93). https://doi.org/10.1016/B978-0-12-800137-0.00003-0
Bishop, T. F. A., McBratney, A. B. et Laslett, G. M. (1999). Modelling soil attribute depth functions with equal-area quadratic smoothing splines. Geoderma, 91(1‑2), 27‑45. https://doi.org/10.1016/S0016-7061(99)00003-8
Malone, B. P., McBratney, A. B., Minasny, B. et Laslett, G. M. (2009). Mapping continuous depth functions of soil carbon storage and available water capacity. Geoderma, 154(1‑2), 138‑152. https://doi.org/10.1016/j.geoderma.2009.10.007
La variable cible doit être un vecteur numérique mesuré sur au moins deux horizons pour que la spline puisse être ajustée. Les profils à un seul horizon sont acceptés et traités conformément aux exigences de sortie, mais aucune spline n’est ajustée en tant que telle.
Seuls les nombres positifs pour les profondeurs supérieures et inférieures peuvent être acceptés. Il est donc important d’enlever les horizons d’humus du jeu de données.
L’ordre des variables dans le fichier d’entrée est important et doit être :
“champ.id” : identifiant du profil. Pour nous il s’agit de id_profil
“champ.prof.sup” : profondeur d’apparition de l’horizon
“champ.prof.inf” : profondeur de disparition de l’horizon
“champ.variable” : valeur de la détermination d’intérêt
ⓘ NOTE
Il faut refaire les splines pour chacune des variables d’intérêt.
Pour les 3 fractions de granulométrie, il faut bien vérifier que la somme boucle à 1000 g/kg dans les splines.
Pour l’exemple, nous ferons les splines sur 3 variables : le pH eau, la teneur en argile et la teneur en carbone (méthode Anne).
3.5.1 Exemples
3.5.1.1 V.1. pH eau
Nous commençons par préparer les données.
# Préparation des données d'entrée des splines
ph <- data.frame("champ.id"=dm_sol$id_profil,
"champ.prof.sup"=dm_sol$prof_sup_moy,
"champ.prof.inf"=dm_sol$prof_inf_moy,
"champ.variable"=dm_sol$ph_eau)
# Nous supprimons les lignes où notre variable d'intérêt est absente
ph <- ph %>% filter(!is.na(champ.variable))
# Nous supprimons les lignes dont les profondeurs sont absentes
ph <- ph %>% filter(!is.na(champ.prof.sup))
# Nous complétons la profondeur de disparition quand celle-ci est absente
# (profondeur de disparition = profondeur d'apparition + 10 cm)
ph$champ.prof.inf<-ifelse(is.na(ph$champ.prof.inf), ph$champ.prof.sup+10, ph$champ.prof.inf)
# Nous mettons les profondeurs ("champ.prof.sup") par ordre croissant
ph <- arrange(ph, champ.id, champ.prof.sup)
# supression des profondeurs négatives
ph <- droplevels(ph[-which(ph$champ.prof.sup<0),])
summary(ph)## champ.id champ.prof.sup champ.prof.inf champ.variable
## Min. : 382 Min. : 0.00 Min. : 3.00 Min. :3.200
## 1st Qu.: 84550 1st Qu.: 0.00 1st Qu.: 30.00 1st Qu.:6.000
## Median : 90446 Median : 30.00 Median : 55.00 Median :6.600
## Mean : 93597 Mean : 34.85 Mean : 64.73 Mean :6.594
## 3rd Qu.:126114 3rd Qu.: 55.00 3rd Qu.: 90.00 3rd Qu.:7.200
## Max. :139441 Max. :200.00 Max. :280.00 Max. :8.900Pour réaliser les splines, nous allons utiliser la fonction “ea_spline” du package ithir. La fonction ea_spline ajuste une spline continue, préservant la masse, depuis la surface du sol jusqu’à la profondeur maximale choisie. Elle interpole de manière fluide à la fois au sein des horizons observés et à travers les lacunes où aucune mesure n’existe. Pour ceux qui souhaite voir la fonction en détail : https://rdrr.io/rforge/ithir/src/R/ea_spline.R
Les couches de profondeurs obtenues sont choisies dans la fonction. Ici, nous choisissons les profondeurs du programme mondial GlobalSoilMap : 0-5, 5-15, 15-30, 30-60, 60-100 et 100-200 cm. Il est bien sûr possible de personnaliser ces profondeurs.
ⓘ Remarque sur les performances :
La fonction ea_spline utilise des calculs internes efficaces et un minimum de dépendances externes, ce qui vous permet de traiter des dizaines de milliers de profils en quelques minutes. Le principal facteur déterminant la durée d’exécution est simplement le nombre total de profils et les intervalles de profondeur.
#Chargement du package ithir
# install.packages("ithir", repos="http://R-Forge.R-project.org") # à faire si le package n'est pas installé
# Réalisation des splines
ph_spline <- ithir::ea_spline(ph, var.name="champ.variable",
d= t(c(0,5,15,30,60,100,200)), # Définit les intervalles de profondeur cibles pour les sorties harmonisées
lam = 0.1, # Paramètre de contrôle de la fluidité des splines
vlow=0, # la plus petite valeur de la variable cible (les valeurs plus petites seront remplacées)
show.progress=FALSE)
# Visualiser le résultat
str(ph_spline)## List of 4
## $ harmonised :'data.frame': 2862 obs. of 8 variables:
## ..$ id : num [1:2862] 382 388 397 413 426 433 438 446 454 458 ...
## ..$ 0-5 cm : num [1:2862] 6.65 5.71 5.38 6.05 5.53 ...
## ..$ 5-15 cm : num [1:2862] 6.67 5.78 5.46 6.27 5.48 ...
## ..$ 15-30 cm : num [1:2862] 6.75 6.1 5.58 7.14 5.27 ...
## ..$ 30-60 cm : num [1:2862] 7 6.64 5.23 6.83 5 ...
## ..$ 60-100 cm : num [1:2862] 7.31 5.7 NA NA NA ...
## ..$ 100-200 cm: num [1:2862] NA 5.25 NA NA NA ...
## ..$ soil depth: num [1:2862] 90 120 55 60 40 70 45 60 60 50 ...
## $ obs.preds :'data.frame': 9295 obs. of 6 variables:
## ..$ champ.id : num [1:9295] 382 382 382 388 388 388 388 397 397 397 ...
## ..$ champ.prof.sup: num [1:9295] 0 30 80 0 30 70 110 0 12 45 ...
## ..$ champ.prof.inf: num [1:9295] 30 80 90 30 70 110 120 12 45 55 ...
## ..$ champ.variable: num [1:9295] 6.7 7.1 7.4 5.9 6.6 5.4 5.3 5.4 5.5 5 ...
## ..$ predicted : num [1:9295] 6.7 7.1 7.4 5.92 6.56 ...
## ..$ FID : num [1:9295] 1 1 1 2 2 2 2 3 3 3 ...
## $ splineFitError:'data.frame': 2862 obs. of 2 variables:
## ..$ rmse : num [1:2862] 0.00269 0.02643 0.01303 0.09193 0.00583 ...
## ..$ rmseiqr: num [1:2862] 0.00767 0.03776 0.05213 0.06566 0.02913 ...
## $ var.1cm : num [1:200, 1:2862] 6.65 6.65 6.65 6.65 6.65 ...Les résultats contiennent 4 objets :
- ph_spline$harmonised : valeurs harmonisées par profil et profondeur
- ph_spline$obs.preds : valeurs observées vs prédites par horizon
- ph_spline$splineFitError : RMSE et nRMSE (RMSE_IQR) pour chaque profil
- ph_spline$var.1cm : courbes splines haute résolution
Avec plusieurs profils, le résultat devient plus intuitif. En particulier, le cadre de données harmonisé “ph_spline$harmonised” répertorie une ligne par profil, chaque colonne représentant la valeur prévue à une profondeur spécifiée par l’utilisateur. La colonne “soil.depth” indique la profondeur maximale de chaque profil, ce qui vous aide à vérifier que les estimations harmonisées couvrent toute la plage observée.
Nous pouvons faire un graphique avec les valeurs prédites et mesurées à partir de “obs.preds”.
# Réalisation du graphique prédit / mesuré
plot(ph_spline$obs.preds$predicted,
ph_spline$obs.preds$champ.variable,
xlab="pH prédit par les splines",
ylab = "pH mesuré",
ylim = c(2,10),
xlim = c(2,10))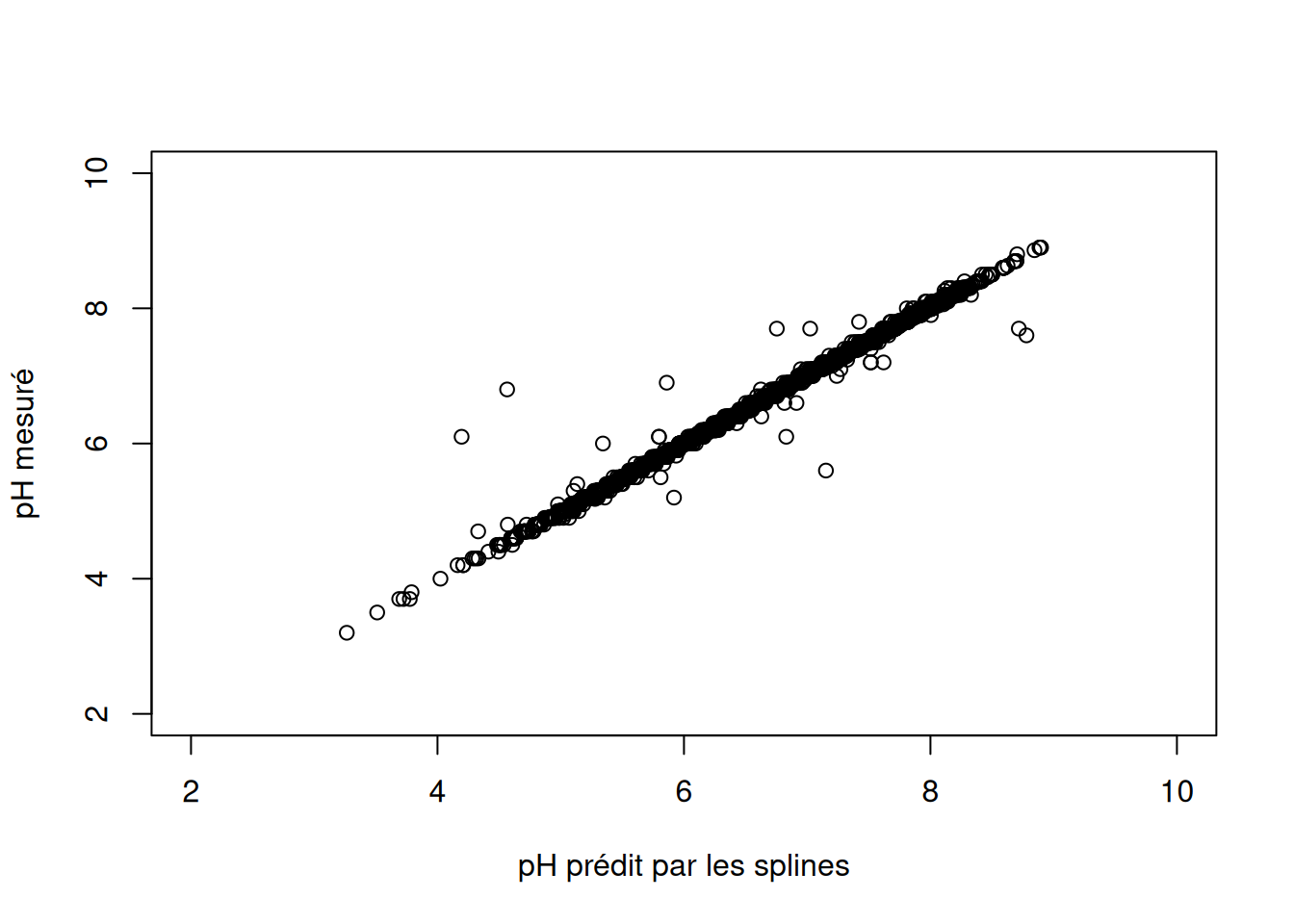
A partir de “splineFitError”, nous pouvons analyser les erreurs issues des splines. Pour cela, nous avons 2 métriques disponibles :
- La RMSE est la racine de l’erreur quadratique moyenne correspondant à l’écart-type des résidus (erreurs de prédiction).
\[ RMSE = \sqrt {\sum_{i = 1}^{n}\frac{(\hat{y_i} - y_i)^2}{n}} \] où \(\hat{y_i}\) sont les valeurs prédites, \({y_i}\) les valeurs mesurées et n le nombre de données.
- La RMSEIQR est la RMSE divisée par l’écart interquartile. Cette valeur normalisée devient moins sensible aux valeurs extrêmes de la variable cible.
\[ RMSE_{IQR} = \frac{RMSE}{Q3-Q1} \] où Q1 est le quantile 0,25 et Q3 le quantile 0,75.
L’unité de ces 2 métriques est la même que la variable (ici, unité pH).
boxplot(ph_spline$splineFitError$rmse,
ph_spline$splineFitError$rmseiqr,
names=c("RMSE","RMSEIQR"), # nom des boxplots
horizontal=T, # mettre le boxplot horizontal
xlab="unité pH", # label de l'axe X
col=c("dodgerblue2","darkorchid"), # couleurs des boxplots
ylim = c(0, 0.1), # fourchette de valeurs de l'axe Y (ici horizontal)
pch = 20) # format des points## Warning in bplt(at[i], wid = width[i], stats = z$stats[, i], out =
## z$out[z$group == : Une valeur extrême (Inf) dans la boite de dispersion 2 n'est
## pas représentée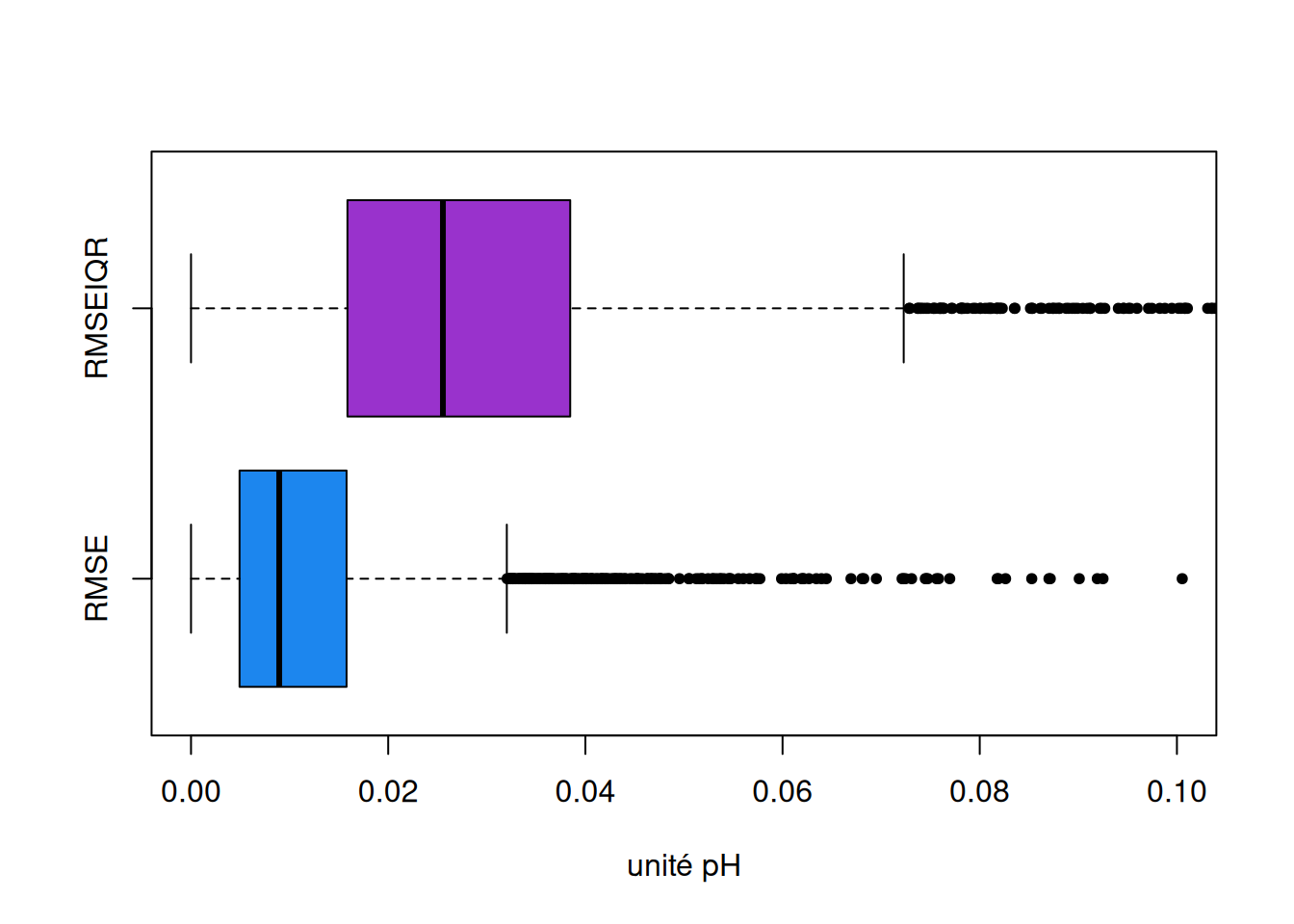
Nous pouvons analyser les résultats, en regardant par exemple l’histogramme de la couche 0-5 cm :
summary(ph_spline$harmonised)## id 0-5 cm 5-15 cm 15-30 cm
## Min. : 382 Min. :2.974 Min. :0.4027 Min. :-9999.000
## 1st Qu.: 84575 1st Qu.:5.850 1st Qu.:5.9000 1st Qu.: 6.038
## Median : 90644 Median :6.219 Median :6.2722 Median : 6.417
## Mean : 94133 Mean :6.300 Mean :6.3429 Mean : -21.465
## 3rd Qu.:127120 3rd Qu.:6.655 3rd Qu.:6.6907 3rd Qu.: 6.902
## Max. :139441 Max. :9.512 Max. :8.5625 Max. : 30.207
## NA's :2
## 30-60 cm 60-100 cm 100-200 cm soil depth
## Min. :-9999.000 Min. :-9999.000 Min. :-9999.000 Min. : 9.00
## 1st Qu.: 6.170 1st Qu.: 5.796 1st Qu.: 5.183 1st Qu.: 65.00
## Median : 6.691 Median : 6.688 Median : 6.332 Median : 91.00
## Mean : -394.867 Mean : -560.547 Mean :-1035.637 Mean : 95.77
## 3rd Qu.: 7.300 3rd Qu.: 7.344 3rd Qu.: 7.163 3rd Qu.:120.00
## Max. : 19.909 Max. : 31.923 Max. : 9.116 Max. :280.00
## NA's :22 NA's :516 NA's :1585
hist(ph_spline$harmonised$`0-5 cm`, breaks= 100, col="darkcyan", main="Histogramme couche 0-5 cm",
xlab = "pH eau")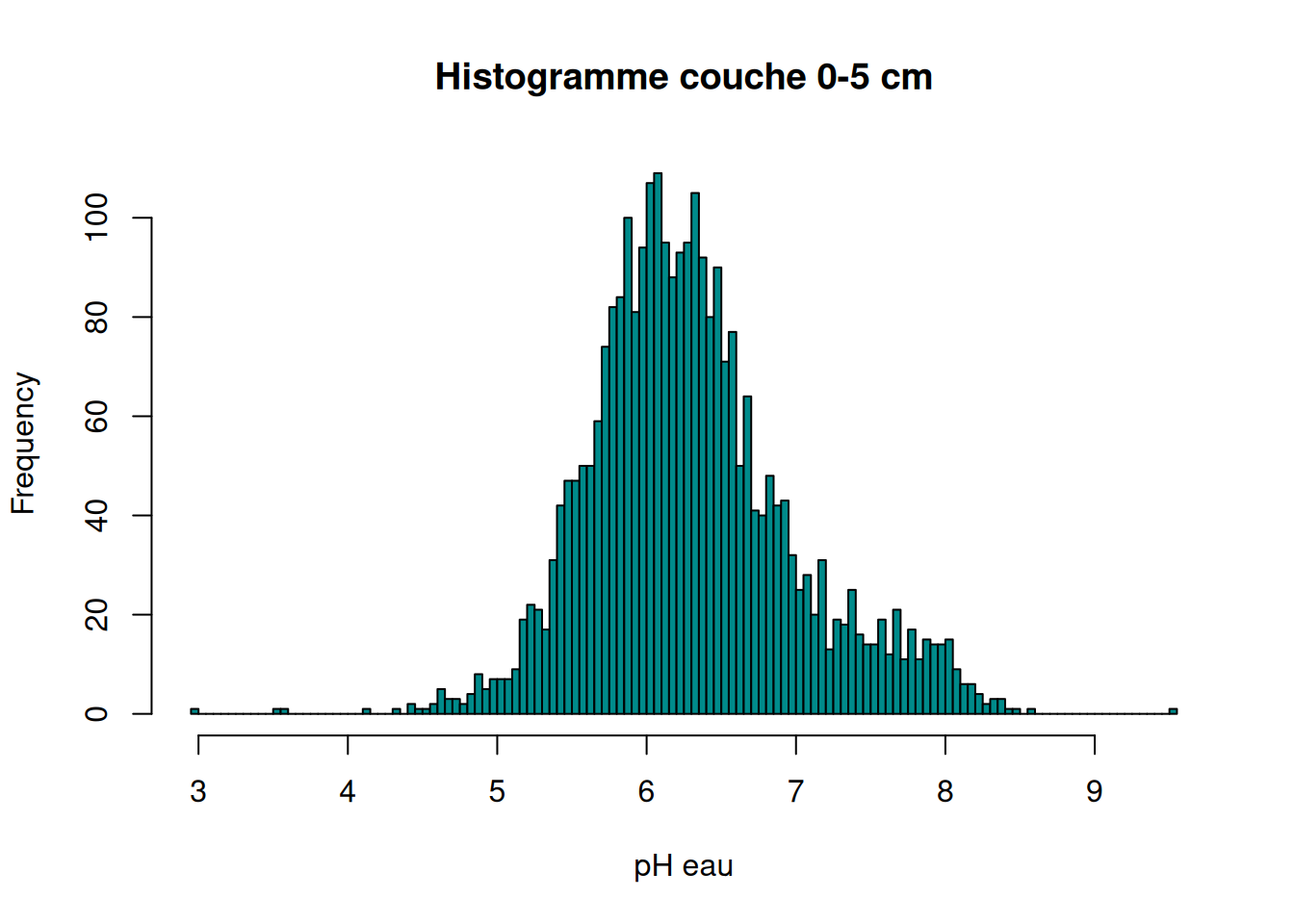
Nous allons faire le cartogramme du pH de la profondeur 0-5 cm. Pour cela, nous allons utiliser le fond de carte de la partie I.2.2.
# Nous rapatrions les coordonnées XY sur les résultats des splines
ph <- ph_spline$harmonised
ph <- left_join(ph, poi, by=c("id"="id_profil"))
# supression des points sans coordonnées
ph <-ph %>% filter(!is.na(x_l93))
ph <-ph %>% filter(!is.na(y_l93))
# Nous convertissons les données XY en fichier spatial
ph <- st_as_sf(ph, coords = c("x_l93", "y_l93"), crs = st_crs(mayenne))
# Pour ne conserver que les points de la zone d'étude
ph <- st_join(ph, mayenne, left = FALSE)
library("ggspatial")
ggplot() +
geom_sf(data = mayenne) +
geom_sf(data = ph, aes(color = `0-5 cm`))+
scale_color_viridis_c(option = "C") + # lettre indiquant l'option de couleurs
theme(legend.position = "right") + # position de la légende
labs(title = "pH couche 0-5 cm", fill = "pH eau") + # titre du graphique
labs(color="pH") + # titre de la légende
theme(legend.title = element_text(color="black", size=10, face = "bold"))+ # formet du texte de la légende
theme_void() +
# ajout d'une échelle
annotation_scale(location = "bl",
line_width = 0.5,
style="ticks",
width_hint = 0.1,
text_face=1,
pad_x = unit(0, "in"),
pad_y = unit(0, "in"),) +
# ajout d'une flèche Nord
annotation_north_arrow(location = "tl",
which_north = "true",
pad_x = unit(-0.09, "in"),
pad_y = unit(0.1, "in"),
style = ggspatial::north_arrow_nautical(
fill = c("grey40", "white"),
line_col = "grey20",
text_family = "ArcherPro Book"))## Ignoring unknown labels:
## • fill : "pH eau"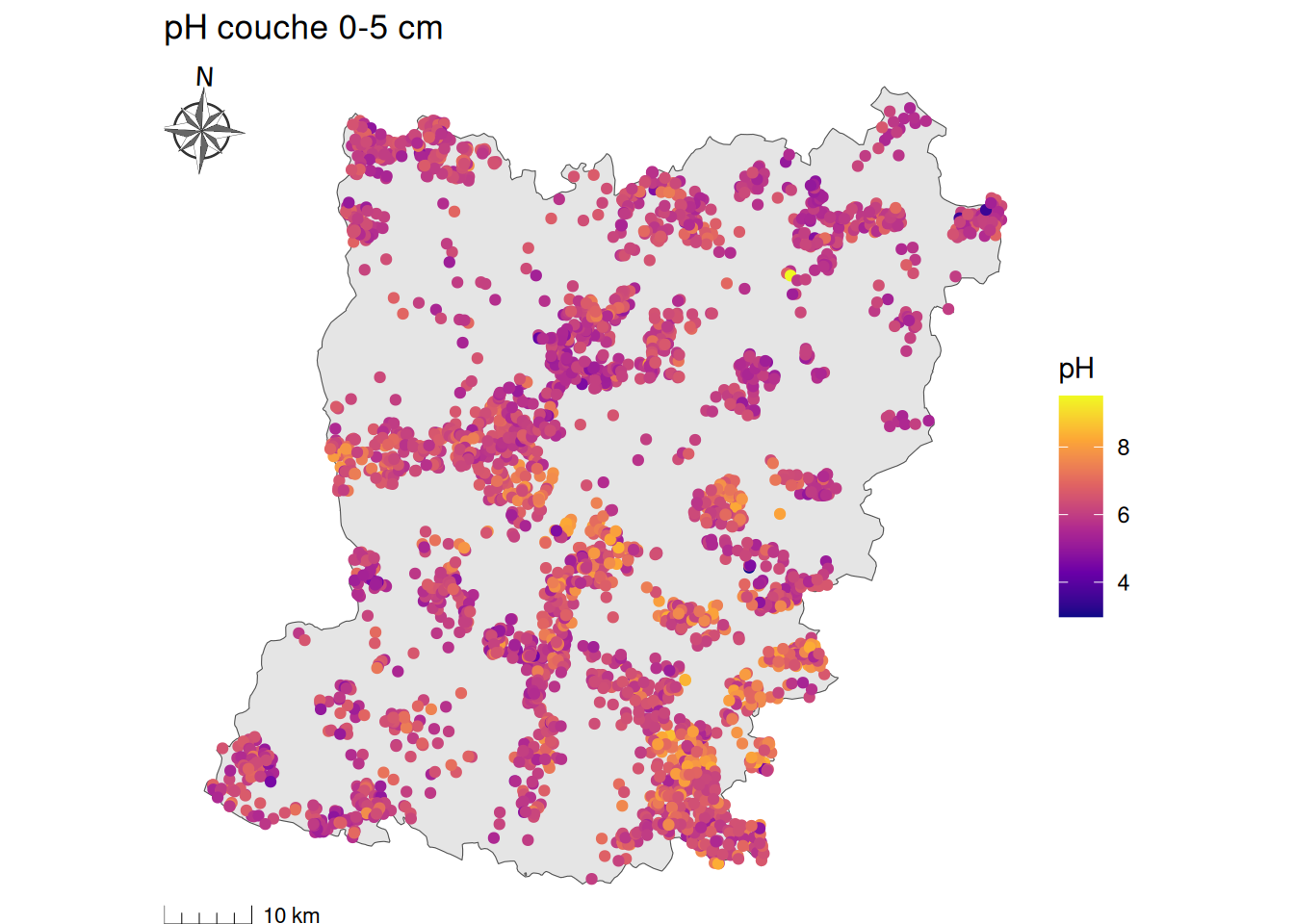
Nous pouvons aussi sortir les cartogrammes de toutes les profondeurs sur une seule figure. Pour cela, nous créons un objet par graphique et nous les regroupons tous à la fin.
plot1 <- ggplot() +
geom_sf(data = mayenne) +
geom_sf(data = ph, aes(color = `0-5 cm`))+
scale_color_viridis_c(option = "H", limits=c(3, 9), na.value = "transparent") +
theme(legend.position = "right") +
labs(title = "pH 0-5 cm", fill = "pH eau") +
labs(color="pH") +
theme(legend.title = element_text(color="black", size=10, face = "bold"))+
theme_void()+
annotation_scale(location = "bl", line_width = 0.5, style="ticks", width_hint = 0.1, text_face=1,
pad_x = unit(0, "in"), pad_y = unit(0, "in"),) + # ajout d'une échelle
annotation_north_arrow(location = "br", which_north = "true", # ajout d'une flèche Nord
pad_x = unit(-0.09, "in"), pad_y = unit(0.1, "in"),
style = ggspatial::north_arrow_nautical(
fill = c("grey40", "white"),
line_col = "grey20",
text_family = "ArcherPro Book"))
plot2 <- ggplot() +
geom_sf(data = mayenne) +
geom_sf(data = ph, aes(color = `5-15 cm`))+
scale_color_viridis_c(option = "H", limits=c(3, 9), na.value = "transparent") +
theme(legend.position = "right") +
labs(title = "pH 5-15 cm", fill = "pH eau") +
labs(color="pH") +
theme(legend.title = element_text(color="black", size=10, face = "bold"))+
theme_void()+
annotation_scale(location = "bl", line_width = 0.5, style="ticks", width_hint = 0.1, text_face=1,
pad_x = unit(0, "in"), pad_y = unit(0, "in"),) + # ajout d'une échelle
annotation_north_arrow(location = "br", which_north = "true", # ajout d'une flèche Nord
pad_x = unit(-0.09, "in"), pad_y = unit(0.1, "in"),
style = ggspatial::north_arrow_nautical(
fill = c("grey40", "white"),
line_col = "grey20",
text_family = "ArcherPro Book"))
plot3 <- ggplot() +
geom_sf(data = mayenne) +
geom_sf(data = ph, aes(color = `15-30 cm`))+
scale_color_viridis_c(option = "H", limits=c(3, 9), na.value = "transparent") +
theme(legend.position = "right") +
labs(title = "pH 15-30 cm", fill = "pH eau") +
labs(color="pH") +
theme(legend.title = element_text(color="black", size=10, face = "bold"))+
theme_void()+
annotation_scale(location = "bl", line_width = 0.5, style="ticks", width_hint = 0.1, text_face=1,
pad_x = unit(0, "in"), pad_y = unit(0, "in"),) + # ajout d'une échelle
annotation_north_arrow(location = "br", which_north = "true", # ajout d'une flèche Nord
pad_x = unit(-0.09, "in"), pad_y = unit(0.1, "in"),
style = ggspatial::north_arrow_nautical(
fill = c("grey40", "white"),
line_col = "grey20",
text_family = "ArcherPro Book"))
plot4 <- ggplot() +
geom_sf(data = mayenne) +
geom_sf(data = ph, aes(color = `30-60 cm`))+
scale_color_viridis_c(option = "H", limits=c(3, 9), na.value = "transparent") +
theme(legend.position = "right") +
labs(title = "pH 30-60 cm", fill = "pH eau") +
labs(color="pH") +
theme(legend.title = element_text(color="black", size=10, face = "bold"))+
theme_void()+
annotation_scale(location = "bl", line_width = 0.5, style="ticks", width_hint = 0.1, text_face=1,
pad_x = unit(0, "in"), pad_y = unit(0, "in"),) + # ajout d'une échelle
annotation_north_arrow(location = "br", which_north = "true", # ajout d'une flèche Nord
pad_x = unit(-0.09, "in"), pad_y = unit(0.1, "in"),
style = ggspatial::north_arrow_nautical(
fill = c("grey40", "white"),
line_col = "grey20",
text_family = "ArcherPro Book"))
plot5 <- ggplot() +
geom_sf(data = mayenne) +
geom_sf(data = ph, aes(color = `60-100 cm`))+
scale_color_viridis_c(option = "H", limits=c(3, 9), na.value = "transparent") +
theme(legend.position = "right") +
labs(title = "pH 60-100 cm", fill = "pH eau") +
labs(color="pH") +
theme(legend.title = element_text(color="black", size=10, face = "bold"))+
theme_void()+
annotation_scale(location = "bl", line_width = 0.5, style="ticks", width_hint = 0.1, text_face=1,
pad_x = unit(0, "in"), pad_y = unit(0, "in"),) + # ajout d'une échelle
annotation_north_arrow(location = "br", which_north = "true", # ajout d'une flèche Nord
pad_x = unit(-0.09, "in"), pad_y = unit(0.1, "in"),
style = ggspatial::north_arrow_nautical(
fill = c("grey40", "white"),
line_col = "grey20",
text_family = "ArcherPro Book"))
plot6 <-ggplot() +
geom_sf(data = mayenne) +
geom_sf(data = ph, aes(color = `100-200 cm`))+
scale_color_viridis_c(option = "H", limits=c(3, 9), na.value = "transparent") +
theme(legend.position = "right") +
labs(title = "pH 100-200 cm", fill = "pH eau") +
labs(color="pH") +
theme(legend.title = element_text(color="black", size=10, face = "bold"))+
theme_void()+
annotation_scale(location = "bl", line_width = 0.5, style="ticks", width_hint = 0.1, text_face=1,
pad_x = unit(0, "in"), pad_y = unit(0, "in"),) + # ajout d'une échelle
annotation_north_arrow(location = "br", which_north = "true", # ajout d'une flèche Nord
pad_x = unit(-0.09, "in"), pad_y = unit(0.1, "in"),
style = ggspatial::north_arrow_nautical(
fill = c("grey40", "white"),
line_col = "grey20",
text_family = "ArcherPro Book"))
plot_grid(plot1, plot2, plot3, plot4, plot5, plot6)## Ignoring unknown labels:
## • fill : "pH eau"
## Ignoring unknown labels:
## • fill : "pH eau"
## Ignoring unknown labels:
## • fill : "pH eau"
## Ignoring unknown labels:
## • fill : "pH eau"
## Ignoring unknown labels:
## • fill : "pH eau"
## Ignoring unknown labels:
## • fill : "pH eau"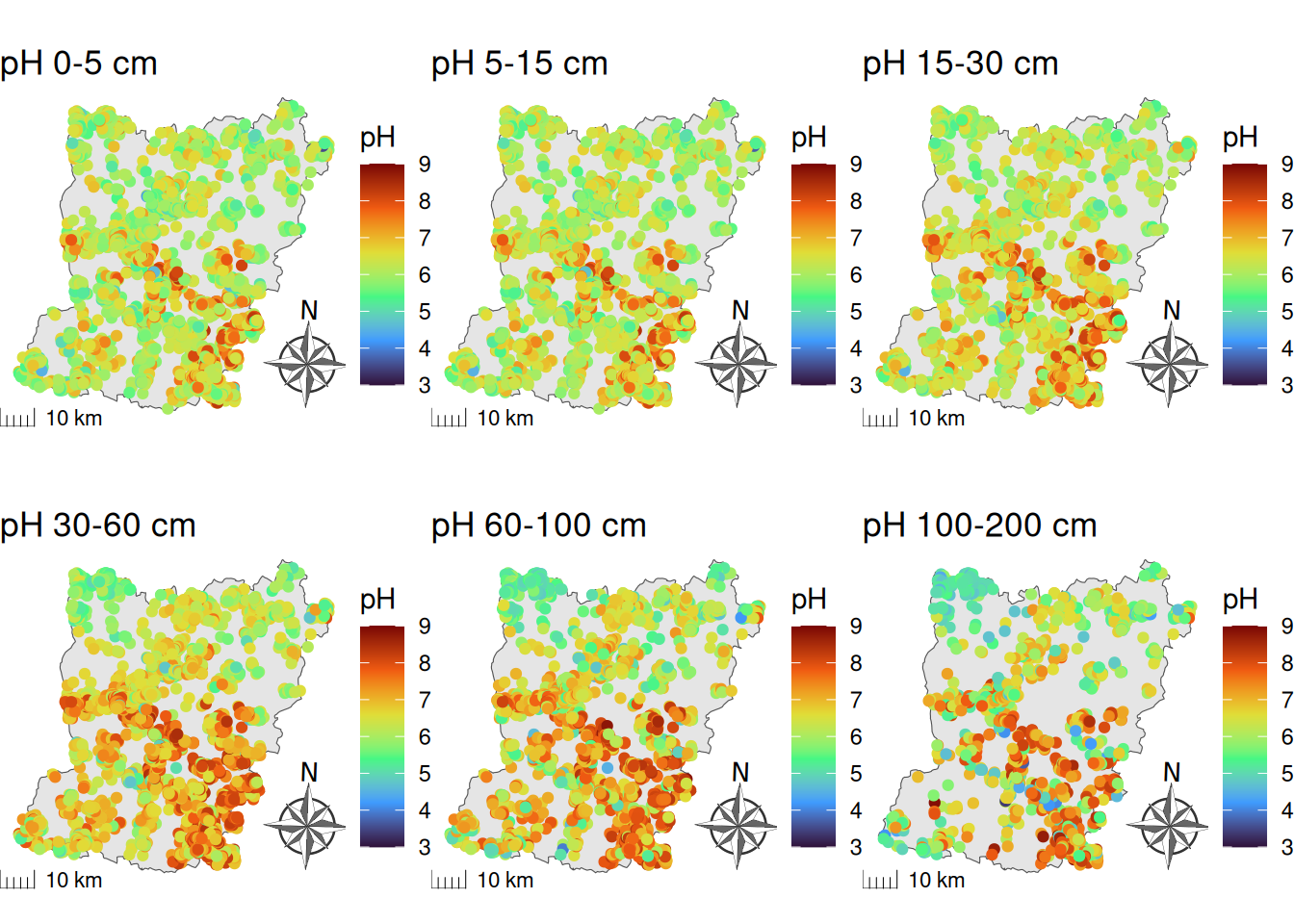
3.5.1.2 V.2. Teneur en argile
Pour notre second exemple, nous ferons la teneur en argile (g/kg). Si nous voulons faire les 3 fractions, il faudra s’assurer que la somme des 3 fractions en sortie des splines bouche bien à 1000 g/kg.
# Préparation des données d'entrée des splines
argile <- data.frame("champ.id"=dm_sol$id_profil,
"champ.prof.sup"=dm_sol$prof_sup_moy,
"champ.prof.inf"=dm_sol$prof_inf_moy,
"champ.variable"=dm_sol$argile)
# Nous supprimons les lignes où notre variable d'intérêt est absente
argile <- argile %>% filter(!is.na(champ.variable))
# Nous complétons la profondeur de disparition quand celle-ci est absente (profondeur de disparition = profondeur d'apparition + 10 cm)
argile$champ.prof.inf<-ifelse(is.na(argile$champ.prof.inf), argile$champ.prof.sup+10, argile$champ.prof.inf)
# Nous mettons les profondeurs ("champ.prof.sup") par ordre croissant
argile <- arrange(argile, champ.id, champ.prof.sup)
# Nous supprimons les lignes dont les profondeurs sont absentes
argile <- argile %>% filter(!is.na(champ.prof.sup))
summary(argile) # vérification des données## champ.id champ.prof.sup champ.prof.inf champ.variable
## Min. : 382 Min. : -7.00 Min. : -2.00 Min. : 9.793
## 1st Qu.: 84551 1st Qu.: 0.00 1st Qu.: 30.00 1st Qu.:143.143
## Median : 90447 Median : 30.00 Median : 55.00 Median :182.000
## Mean : 93606 Mean : 34.85 Mean : 64.73 Mean :204.134
## 3rd Qu.:126114 3rd Qu.: 55.00 3rd Qu.: 90.00 3rd Qu.:238.000
## Max. :139441 Max. :200.00 Max. :280.00 Max. :858.142
# supression des profondeurs négatives
argile <- droplevels(argile[-which(argile$champ.prof.sup<0),]) Pour réaliser les splines, nous allons utiliser la fonction “ea_spline” du package ithir. La fonction ea_spline ajuste une spline continue, préservant la masse, depuis la surface du sol jusqu’à la profondeur maximale choisie. Elle interpole de manière fluide à la fois au sein des horizons observés et à travers les lacunes où aucune mesure n’existe.
#Chargement du package ithir
# install.packages("ithir", repos="http://R-Forge.R-project.org")
# Réalisation des splines
argile_spline <- ithir::ea_spline(argile, var.name="champ.variable",
d= t(c(0,5,15,30,60,100,200)), # Définit les intervalles de profondeur cibles pour les sorties harmonisées
lam = 0.1, # Paramètre de contrôle de la fluidité des splines
vlow=0, # la plus petite valeur de la variable cible (les valeurs plus petites seront remplacées)
show.progress=FALSE)
# Visualiser le résultat
str(argile_spline)## List of 4
## $ harmonised :'data.frame': 2862 obs. of 8 variables:
## ..$ id : num [1:2862] 382 388 397 413 426 433 438 446 454 458 ...
## ..$ 0-5 cm : num [1:2862] 217.9 345.5 250.6 195.1 32.2 ...
## ..$ 5-15 cm : num [1:2862] 220.2 333.4 196.1 209.7 70.1 ...
## ..$ 15-30 cm : num [1:2862] 230 285 141 268 222 ...
## ..$ 30-60 cm : num [1:2862] 251 217 459 358 419 ...
## ..$ 60-100 cm : num [1:2862] 253 463 NA NA NA ...
## ..$ 100-200 cm: num [1:2862] NA 634 NA NA NA ...
## ..$ soil depth: num [1:2862] 90 120 55 60 40 70 45 60 60 50 ...
## $ obs.preds :'data.frame': 9305 obs. of 6 variables:
## ..$ champ.id : num [1:9305] 382 382 382 388 388 388 388 397 397 397 ...
## ..$ champ.prof.sup: num [1:9305] 0 30 80 0 30 70 110 0 12 45 ...
## ..$ champ.prof.inf: num [1:9305] 30 80 90 30 70 110 120 12 45 55 ...
## ..$ champ.variable: num [1:9305] 224 253 247 316 232 ...
## ..$ predicted : num [1:9305] 224 252 247 313 240 ...
## ..$ FID : num [1:9305] 1 1 1 2 2 2 2 3 3 3 ...
## $ splineFitError:'data.frame': 2862 obs. of 2 variables:
## ..$ rmse : num [1:2862] 0.452 4.702 10.195 2.522 4.238 ...
## ..$ rmseiqr: num [1:2862] 0.0309 0.0172 0.0462 0.0385 0.0291 ...
## $ var.1cm : num [1:200, 1:2862] 218 218 218 218 218 ...Les résultats contiennent 4 objets :
- argile_spline$harmonised : valeurs harmonisées par profil et profondeur
- argile_spline$obs.preds : valeurs observées vs prédites par horizon
- argile_spline$splineFitError : RMSE et nRMSE pour chaque profil
- argile_spline$var.1cm : courbes splines haute résolution
Nous pouvons faire un graphique avec les valeurs prédites et mesurées à partir de “obs.preds”.
# Réalisation du graphique prédit / mesuré
plot(argile_spline$obs.preds$predicted,
argile_spline$obs.preds$champ.variable,
xlab="teneur en argile prédite par les splines (g/kg)",
ylab = "teneur en argile mesurée (g/kg)",
xlim=c(0, 1000),
ylim=c(0, 1000))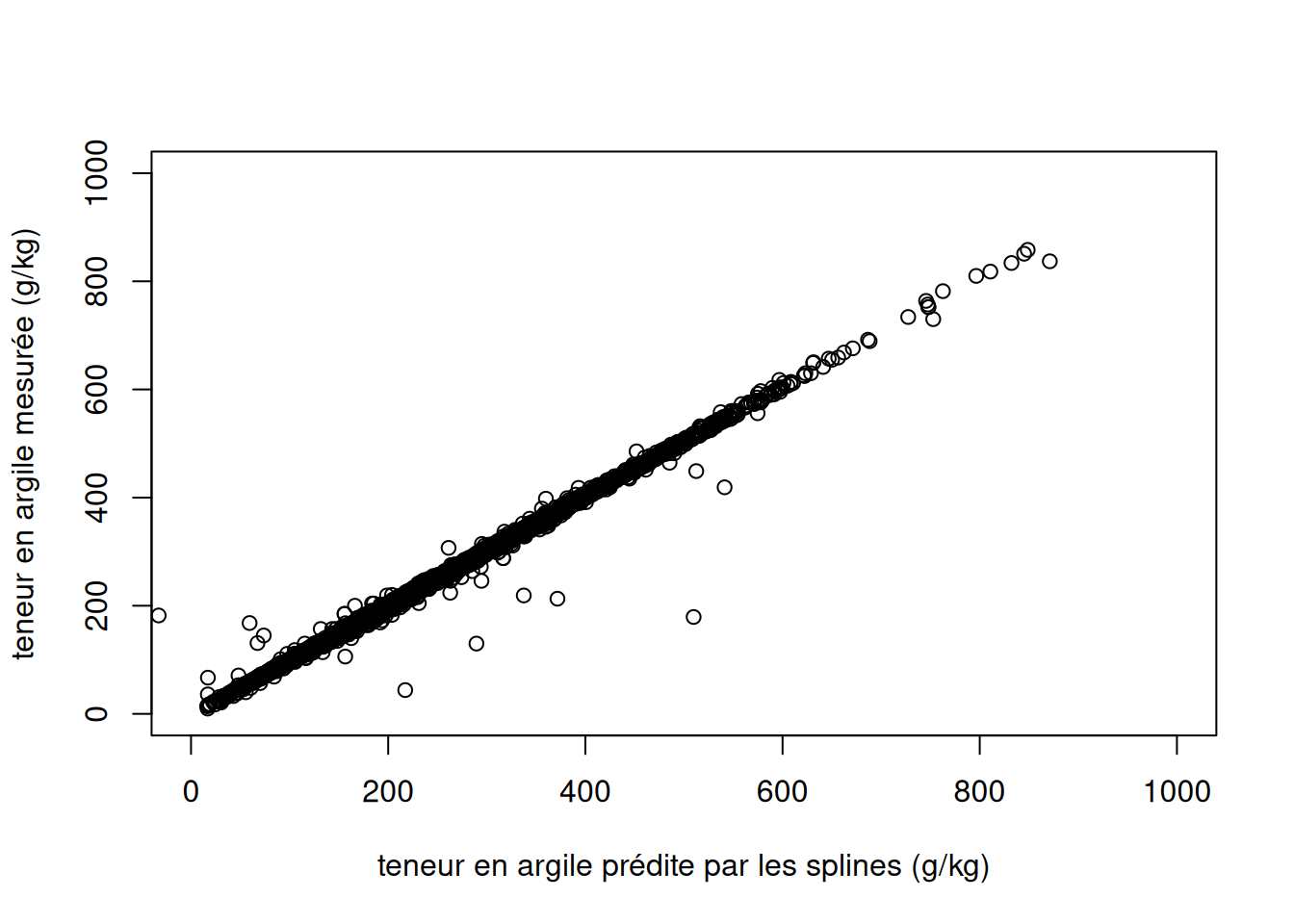
summary(argile_spline$harmonised)## id 0-5 cm 5-15 cm 15-30 cm
## Min. : 382 Min. : 0.0 Min. : 0.0 Min. :-9999.0
## 1st Qu.: 84575 1st Qu.:139.0 1st Qu.:139.2 1st Qu.: 136.7
## Median : 90644 Median :162.3 Median :162.6 Median : 164.7
## Mean : 94133 Mean :176.5 Mean :177.1 Mean : 150.8
## 3rd Qu.:127120 3rd Qu.:200.6 3rd Qu.:200.0 3rd Qu.: 204.7
## Max. :139441 Max. :650.9 Max. :871.3 Max. : 600.0
## NA's :2
## 30-60 cm 60-100 cm 100-200 cm soil depth
## Min. :-9999.0 Min. :-9999.0 Min. :-9999.0 Min. : 9.00
## 1st Qu.: 135.0 1st Qu.: 151.8 1st Qu.: 141.0 1st Qu.: 65.25
## Median : 176.8 Median : 206.4 Median : 204.3 Median : 92.00
## Mean : -211.5 Mean : -346.6 Mean : -818.8 Mean : 95.83
## 3rd Qu.: 229.0 3rd Qu.: 278.1 3rd Qu.: 293.2 3rd Qu.:120.00
## Max. : 834.5 Max. : 1000.0 Max. : 958.4 Max. :280.00
## NA's :22 NA's :515 NA's :1583
hist(argile_spline$harmonised$`0-5 cm`,
breaks= 100,
col="darkgoldenrod1",
main="Histogramme couche 0-5 cm",
xlab = "argile (g/kg)")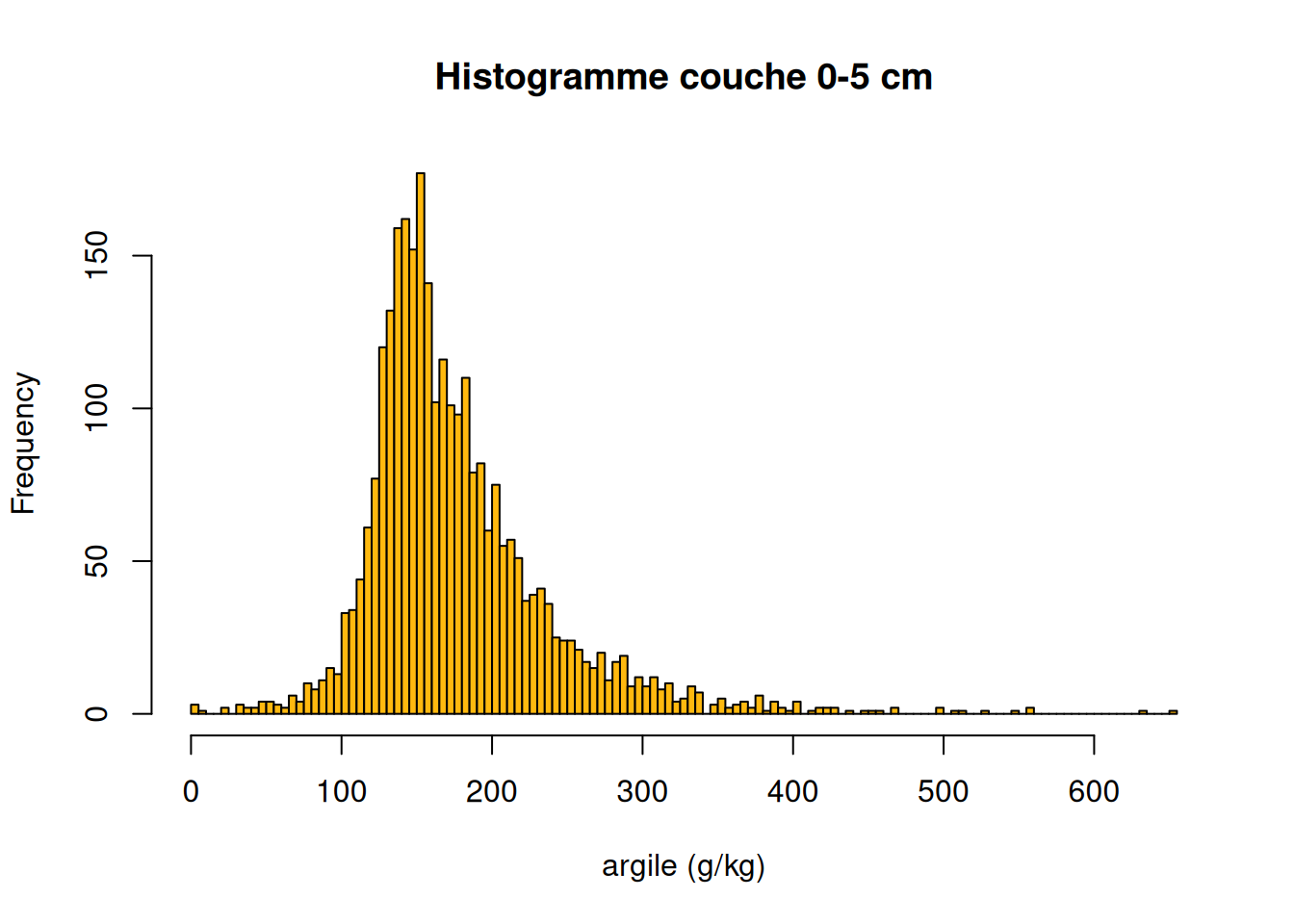
A partir de “splineFitError”, nous pouvons analyser les erreurs issues des splines.
L’unité de ces 2 métriques est la même que la variable (ici, g/kg).
boxplot(argile_spline$splineFitError$rmse,
argile_spline$splineFitError$rmseiqr,
names=c("RMSE","RMSEIQR"), # nom des boxplots
horizontal=T, # mettre le boxplot horizontal
xlab="g/kg", # label de l'axe X
col=c("dodgerblue2","darkorchid"), # couleurs des boxplots
ylim = c(0, 5), # fourchette de valeurs de l'axe Y (ici horizontal)
pch = 20) # format des points## Warning in bplt(at[i], wid = width[i], stats = z$stats[, i], out =
## z$out[z$group == : Une valeur extrême (Inf) dans la boite de dispersion 2 n'est
## pas représentée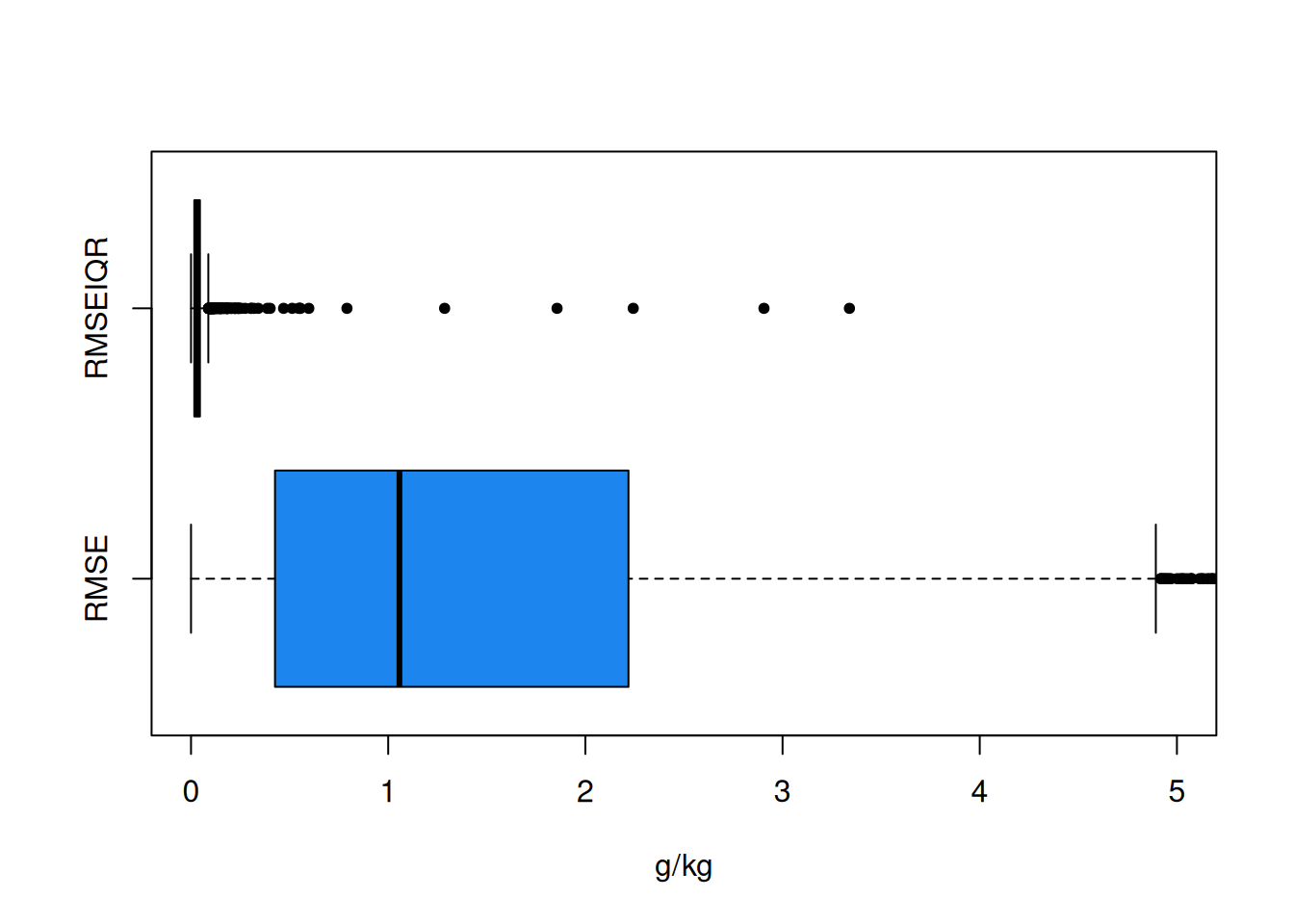
Nous allons faire les cartogrammes des teneurs en argile par couche de profondeurs. Pour cela, nous allons utiliser le fond de carte de la partie I.2.2.
# Nous rapatrions les coordonnées XY sur les résultats des splines
A <- argile_spline$harmonised
A <- left_join(A, poi, by=c("id"="id_profil"))
# supression des points sans coordonnées
A <-A %>% filter(!is.na(x_l93))
A <-A %>% filter(!is.na(y_l93))
# Nous convertissons les données XY en fichier spatial
A <- st_as_sf(A, coords = c("x_l93", "y_l93"), crs = st_crs(mayenne))
# Pour ne conserver que les points de la zone d'étude
A <- st_join(A, mayenne, left = FALSE)
plot7 <- ggplot() +
geom_sf(data = mayenne) +
geom_sf(data = A, aes(color = `0-5 cm`))+
scale_color_viridis_c(option = "H", limits=c(0, 1000), na.value = "transparent") +
theme(legend.position = "right") +
labs(title = "argile 0-5 cm", fill = "argile") +
labs(color="g/kg") +
theme(legend.title = element_text(color="black", size=10, face = "bold"))+
theme_void()+
annotation_scale(location = "bl", line_width = 0.5, style="ticks", width_hint = 0.1, text_face=1,
pad_x = unit(0, "in"), pad_y = unit(0, "in"),) + # ajout d'une échelle
annotation_north_arrow(location = "br", which_north = "true", # ajout d'une flèche Nord
pad_x = unit(-0.09, "in"), pad_y = unit(0.1, "in"),
style = ggspatial::north_arrow_nautical(
fill = c("grey40", "white"),
line_col = "grey20",
text_family = "ArcherPro Book"))
plot8 <- ggplot() +
geom_sf(data = mayenne) +
geom_sf(data = A, aes(color = `5-15 cm`))+
scale_color_viridis_c(option = "H", limits=c(0, 1000), na.value = "transparent") +
theme(legend.position = "right") +
labs(title = "argile 5-15 cm", fill = "argile eau") +
labs(color="g/kg") +
theme(legend.title = element_text(color="black", size=10, face = "bold"))+
theme_void()+
annotation_scale(location = "bl", line_width = 0.5, style="ticks", width_hint = 0.1, text_face=1,
pad_x = unit(0, "in"), pad_y = unit(0, "in"),) + # ajout d'une échelle
annotation_north_arrow(location = "br", which_north = "true", # ajout d'une flèche Nord
pad_x = unit(-0.09, "in"), pad_y = unit(0.1, "in"),
style = ggspatial::north_arrow_nautical(
fill = c("grey40", "white"),
line_col = "grey20",
text_family = "ArcherPro Book"))
plot9 <- ggplot() +
geom_sf(data = mayenne) +
geom_sf(data = A, aes(color = `15-30 cm`))+
scale_color_viridis_c(option = "H", limits=c(0, 1000), na.value = "transparent") +
theme(legend.position = "right") +
labs(title = "argile 15-30 cm", fill = "argile eau") +
labs(color="g/kg") +
theme(legend.title = element_text(color="black", size=10, face = "bold"))+
theme_void()+
annotation_scale(location = "bl", line_width = 0.5, style="ticks", width_hint = 0.1, text_face=1,
pad_x = unit(0, "in"), pad_y = unit(0, "in"),) + # ajout d'une échelle
annotation_north_arrow(location = "br", which_north = "true", # ajout d'une flèche Nord
pad_x = unit(-0.09, "in"), pad_y = unit(0.1, "in"),
style = ggspatial::north_arrow_nautical(
fill = c("grey40", "white"),
line_col = "grey20",
text_family = "ArcherPro Book"))
plot10 <- ggplot() +
geom_sf(data = mayenne) +
geom_sf(data = A, aes(color = `30-60 cm`))+
scale_color_viridis_c(option = "H", limits=c(0, 1000), na.value = "transparent") +
theme(legend.position = "right") +
labs(title = "argile 30-60 cm", fill = "argile eau") +
labs(color="g/kg") +
theme(legend.title = element_text(color="black", size=10, face = "bold"))+
theme_void()+
annotation_scale(location = "bl", line_width = 0.5, style="ticks", width_hint = 0.1, text_face=1,
pad_x = unit(0, "in"), pad_y = unit(0, "in"),) + # ajout d'une échelle
annotation_north_arrow(location = "br", which_north = "true", # ajout d'une flèche Nord
pad_x = unit(-0.09, "in"), pad_y = unit(0.1, "in"),
style = ggspatial::north_arrow_nautical(
fill = c("grey40", "white"),
line_col = "grey20",
text_family = "ArcherPro Book"))
plot11 <- ggplot() +
geom_sf(data = mayenne) +
geom_sf(data = A, aes(color = `60-100 cm`))+
scale_color_viridis_c(option = "H", limits=c(0, 1000), na.value = "transparent") +
theme(legend.position = "right") +
labs(title = "argile 60-100 cm", fill = "argile eau") +
labs(color="g/kg") +
theme(legend.title = element_text(color="black", size=10, face = "bold"))+
theme_void()+
annotation_scale(location = "bl", line_width = 0.5, style="ticks", width_hint = 0.1, text_face=1,
pad_x = unit(0, "in"), pad_y = unit(0, "in"),) + # ajout d'une échelle
annotation_north_arrow(location = "br", which_north = "true", # ajout d'une flèche Nord
pad_x = unit(-0.09, "in"), pad_y = unit(0.1, "in"),
style = ggspatial::north_arrow_nautical(
fill = c("grey40", "white"),
line_col = "grey20",
text_family = "ArcherPro Book"))
plot12 <-ggplot() +
geom_sf(data = mayenne) +
geom_sf(data = A, aes(color = `100-200 cm`))+
scale_color_viridis_c(option = "H", limits=c(0, 1000), na.value = "transparent") +
theme(legend.position = "right") +
labs(title = "argile 100-200 cm", fill = "argile eau") +
labs(color="g/kg") +
theme(legend.title = element_text(color="black", size=10, face = "bold"))+
theme_void()+
annotation_scale(location = "bl", line_width = 0.5, style="ticks", width_hint = 0.1, text_face=1,
pad_x = unit(0, "in"), pad_y = unit(0, "in"),) + # ajout d'une échelle
annotation_north_arrow(location = "br", which_north = "true", # ajout d'une flèche Nord
pad_x = unit(-0.09, "in"), pad_y = unit(0.1, "in"),
style = ggspatial::north_arrow_nautical(
fill = c("grey40", "white"),
line_col = "grey20",
text_family = "ArcherPro Book"))
plot_grid(plot7, plot8, plot9, plot10, plot11, plot12)## Ignoring unknown labels:
## • fill : "argile"
## Ignoring unknown labels:
## • fill : "argile eau"
## Ignoring unknown labels:
## • fill : "argile eau"
## Ignoring unknown labels:
## • fill : "argile eau"
## Ignoring unknown labels:
## • fill : "argile eau"
## Ignoring unknown labels:
## • fill : "argile eau"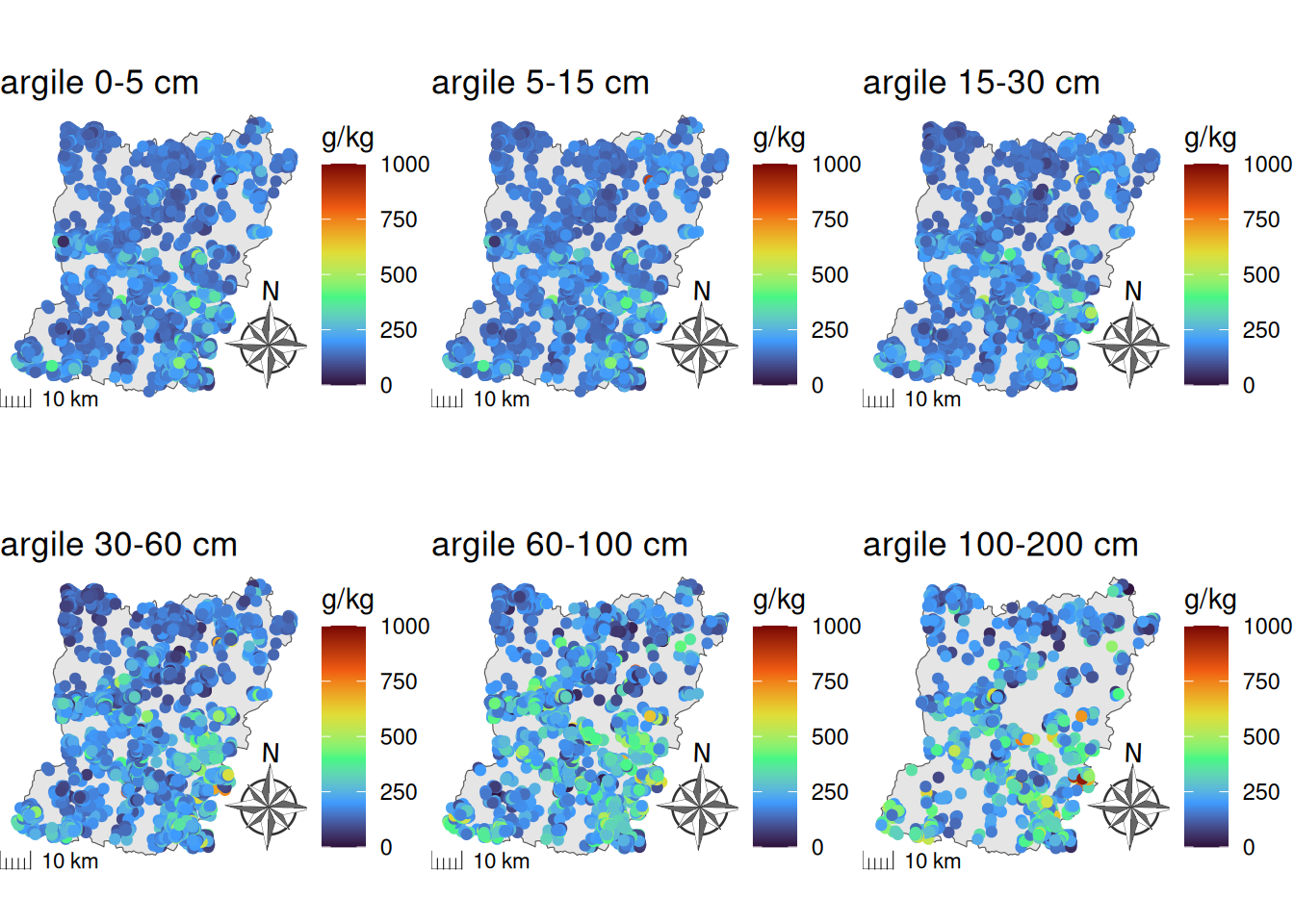
3.5.1.3 V.3. Carbone Anne
Pour notre troisième exemple, nous ferons la teneur en carbone (g/kg) méthode Anne.
# Préparation des données d'entrée des splines
c_anne <- data.frame("champ.id"=dm_sol$id_profil,
"champ.prof.sup"=dm_sol$prof_sup_moy,
"champ.prof.inf"=dm_sol$prof_inf_moy,
"champ.variable"=dm_sol$carbone_anne)
# Nous supprimons les lignes où notre variable d'intérêt est absente
c_anne <- c_anne %>% filter(!is.na(champ.variable))
# Nous complétons la profondeur de disparition quand celle-ci est absente (profondeur de disparition = profondeur d'apparition + 10 cm)
c_anne$champ.prof.inf<-ifelse(is.na(c_anne$champ.prof.inf),
c_anne$champ.prof.sup+10,
c_anne$champ.prof.inf)
# Nous mettons les profondeurs ("champ.prof.sup") par ordre croissant
c_anne <- arrange(c_anne, champ.id, champ.prof.sup)
# Nous supprimons les lignes dont les profondeurs sont absentes
c_anne <- c_anne %>% filter(!is.na(champ.prof.sup))
summary(c_anne) # vérification des données## champ.id champ.prof.sup champ.prof.inf champ.variable
## Min. : 382 Min. : -7.000 Min. : -2.00 Min. : 0.70
## 1st Qu.: 84565 1st Qu.: 0.000 1st Qu.: 25.00 1st Qu.: 12.80
## Median : 90868 Median : 0.000 Median : 30.00 Median : 17.00
## Mean : 93965 Mean : 3.173 Mean : 31.04 Mean : 18.71
## 3rd Qu.:127441 3rd Qu.: 0.000 3rd Qu.: 32.00 3rd Qu.: 22.10
## Max. :139441 Max. :130.000 Max. :200.00 Max. :248.00
# supression des profondeurs négatives
c_anne <- droplevels(c_anne[-which(c_anne$champ.prof.sup<0),]) Pour réaliser les splines, nous allons utiliser la fonction “ea_spline” du package ithir. La fonction ea_spline ajuste une spline continue, préservant la masse, depuis la surface du sol jusqu’à la profondeur maximale choisie. Elle interpole de manière fluide à la fois au sein des horizons observés et à travers les lacunes où aucune mesure n’existe.
#Chargement du package ithir
# install.packages("ithir", repos="http://R-Forge.R-project.org")
# Réalisation des splines
c_anne_spline <- ithir::ea_spline(c_anne, var.name="champ.variable",
d= t(c(0,5,15,30,60,100,200)), # Définit les intervalles de profondeur cibles pour les sorties harmonisées
lam = 0.1, # Paramètre de contrôle de la fluidité des splines
vlow=0, # la plus petite valeur de la variable cible (les valeurs plus petites seront remplacées)
show.progress=FALSE)
# Visualiser le résultat
str(c_anne_spline)## List of 4
## $ harmonised :'data.frame': 2788 obs. of 8 variables:
## ..$ id : num [1:2788] 382 388 397 413 426 433 438 446 454 458 ...
## ..$ 0-5 cm : num [1:2788] 18 23.8 45 15.8 21.8 13.8 16.9 18.5 14.7 28.8 ...
## ..$ 5-15 cm : num [1:2788] 18 23.8 45 15.8 21.8 13.8 16.9 18.5 14.7 28.8 ...
## ..$ 15-30 cm : num [1:2788] 18 23.8 -9999 15.8 21.8 ...
## ..$ 30-60 cm : num [1:2788] -9999 -9999 -9999 -9999 -9999 ...
## ..$ 60-100 cm : num [1:2788] -9999 -9999 -9999 -9999 -9999 ...
## ..$ 100-200 cm: num [1:2788] -9999 -9999 -9999 -9999 -9999 ...
## ..$ soil depth: num [1:2788] 30 30 12 30 30 30 35 25 35 25 ...
## $ obs.preds :'data.frame': 3138 obs. of 6 variables:
## ..$ champ.id : num [1:3138] 382 388 397 413 426 433 438 446 454 458 ...
## ..$ champ.prof.sup: num [1:3138] 0 0 0 0 0 0 0 0 0 0 ...
## ..$ champ.prof.inf: num [1:3138] 30 30 12 30 30 30 35 25 35 25 ...
## ..$ champ.variable: num [1:3138] 18 23.8 45 15.8 21.8 13.8 16.9 18.5 14.7 28.8 ...
## ..$ predicted : num [1:3138] 18 23.8 45 15.8 21.8 13.8 16.9 18.5 14.7 28.8 ...
## ..$ FID : num [1:3138] 1 2 3 4 5 6 7 8 9 10 ...
## $ splineFitError:'data.frame': 2788 obs. of 2 variables:
## ..$ rmse : num [1:2788] 0 0 0 0 0 0 0 0 0 0 ...
## ..$ rmseiqr: num [1:2788] 0 0 0 0 0 0 0 0 0 0 ...
## $ var.1cm : num [1:200, 1:2788] 18 18 18 18 18 18 18 18 18 18 ...Les résultats contiennent 4 objets :
- c_anne_spline$harmonised : valeurs harmonisées par profil et profondeur
- c_anne_spline$obs.preds : valeurs observées vs prédites par horizon
- c_anne_spline$splineFitError : RMSE et nRMSE pour chaque profil
- c_anne_spline$var.1cm : courbes splines haute résolution
Nous pouvons faire un graphique avec les valeurs prédites et mesurées à partir de “obs.preds”.
# Réalisation du graphique prédit / mesuré
plot(c_anne_spline$obs.preds$predicted,
c_anne_spline$obs.preds$champ.variable,
xlab="carbone Anne prédit par les splines (g/kg)",
ylab = "Carbone Anne mesuré (g/kg)",
xlim=c(0, 400),
ylim=c(0, 400))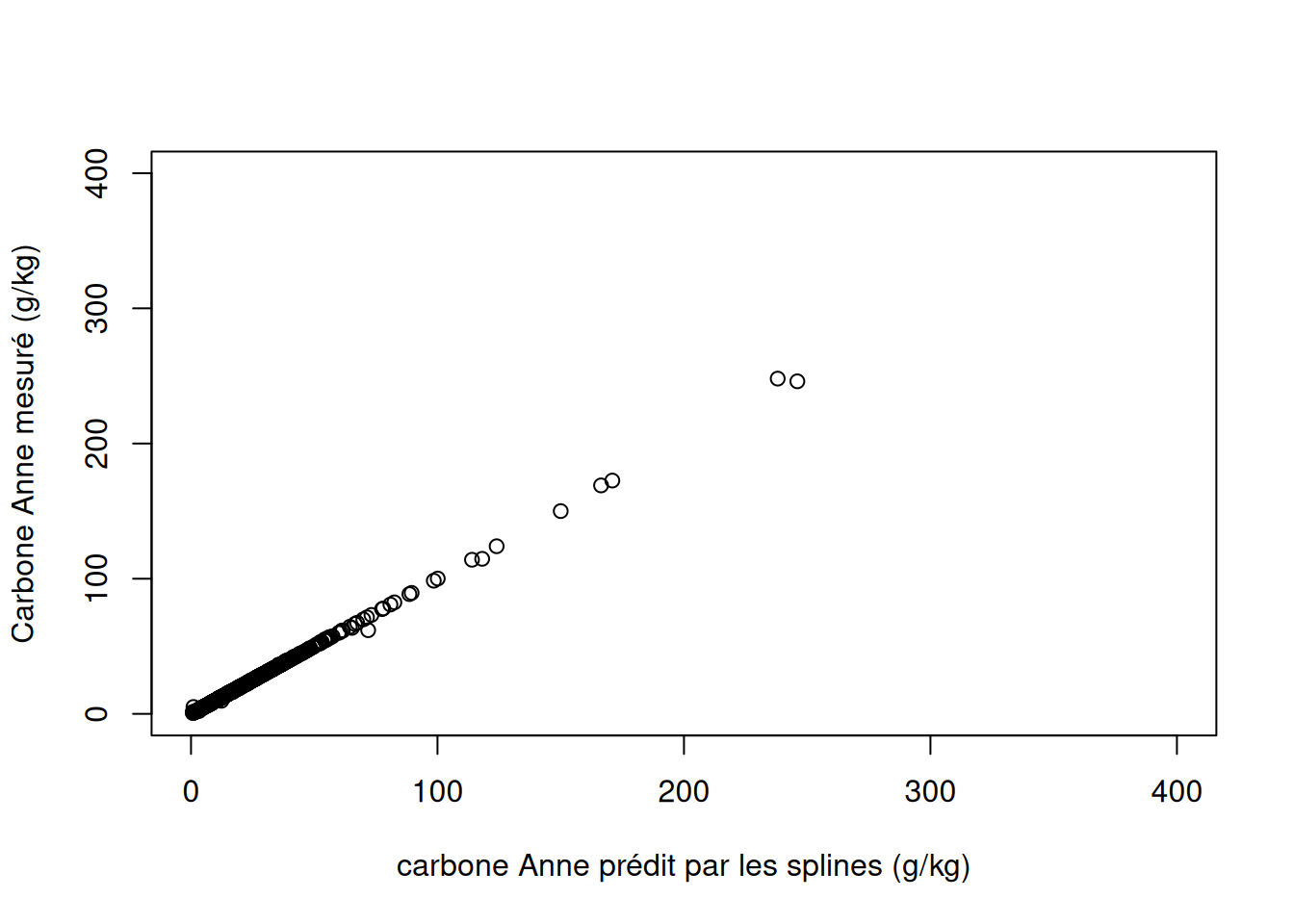
summary(c_anne_spline$harmonised)## id 0-5 cm 5-15 cm 15-30 cm
## Min. : 382 Min. : 0.00 Min. :-9999.000 Min. :-9999.00
## 1st Qu.: 84562 1st Qu.: 14.00 1st Qu.: 13.929 1st Qu.: 13.10
## Median : 90644 Median : 17.90 Median : 17.800 Median : 16.97
## Mean : 93927 Mean : 19.95 Mean : 5.269 Mean : -333.76
## 3rd Qu.:126131 3rd Qu.: 22.90 3rd Qu.: 22.800 3rd Qu.: 21.60
## Max. :139441 Max. :246.00 Max. : 246.000 Max. : 246.00
## NA's :3
## 30-60 cm 60-100 cm 100-200 cm soil depth
## Min. :-9999.000 Min. :-9999.0 Min. :-9999.00 Min. : 3.00
## 1st Qu.:-9999.000 1st Qu.:-9999.0 1st Qu.:-9999.00 1st Qu.: 25.00
## Median :-9999.000 Median :-9999.0 Median :-9999.00 Median : 30.00
## Mean :-7287.836 Mean :-9603.8 Mean :-9927.02 Mean : 31.07
## 3rd Qu.: 4.092 3rd Qu.:-9999.0 3rd Qu.:-9999.00 3rd Qu.: 32.00
## Max. : 191.323 Max. : 44.3 Max. : 19.32 Max. :200.00
## NA's :40 NA's :206 NA's :286
hist(c_anne_spline$harmonised$`0-5 cm`,
breaks= 100,
col="darkgoldenrod1",
main="Histogramme couche 0-5 cm",
xlab = "c_anne (g/kg)")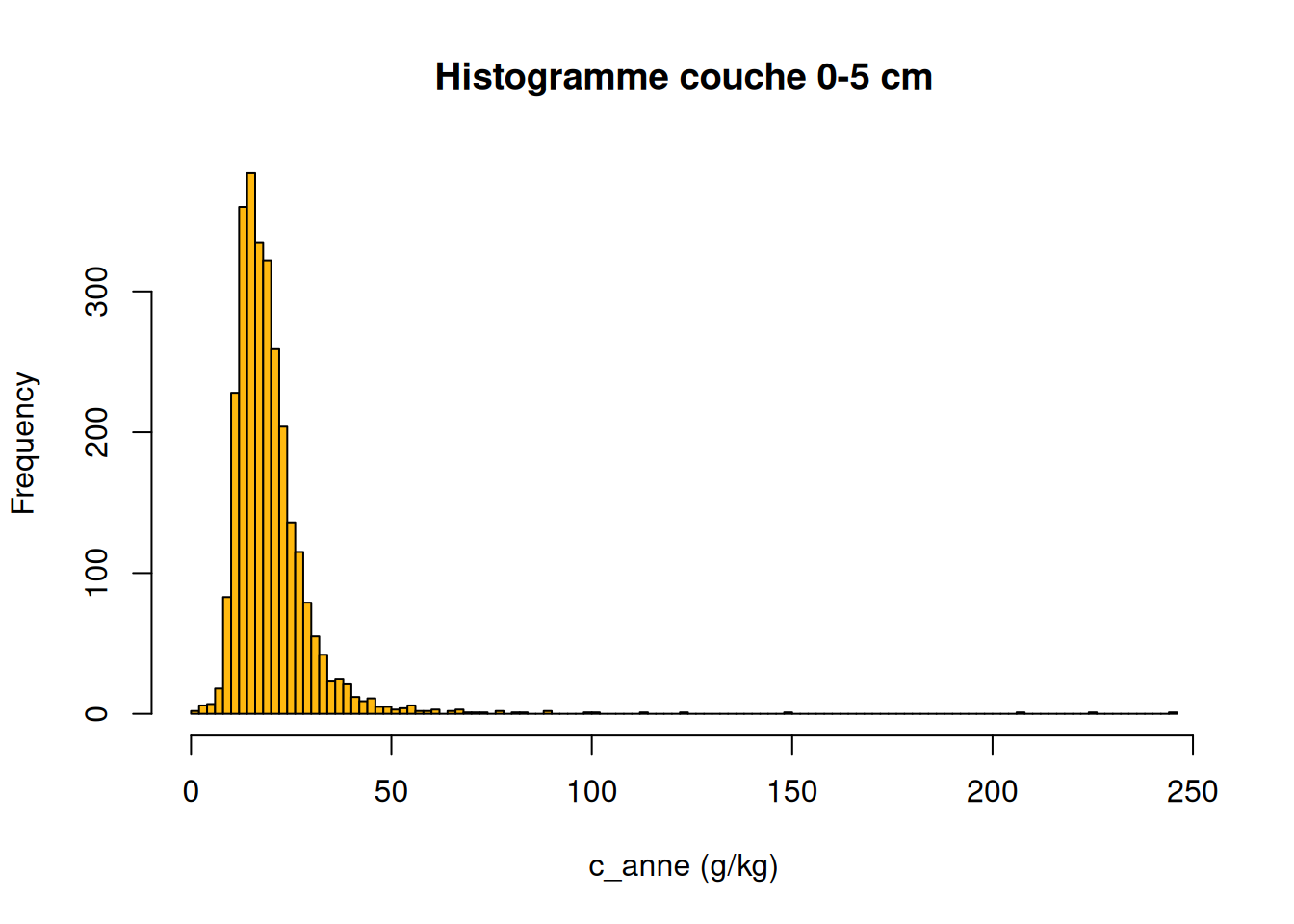
A partir de “splineFitError”, nous pouvons analyser les erreurs issues des splines.
L’unité de ces 2 métriques est la même que la variable (ici, g/kg).
boxplot(c_anne_spline$splineFitError$rmse,
c_anne_spline$splineFitError$rmseiqr,
names=c("RMSE","RMSEIQR"), # nom des boxplots
horizontal=T, # mettre le boxplot horizontal
xlab="g/kg", # label de l'axe X
col=c("dodgerblue2","darkorchid"), # couleurs des boxplots
ylim = c(0, 0.5), # fourchette de valeurs de l'axe Y (ici horizontal)
pch = 20) # format des points## Warning in bplt(at[i], wid = width[i], stats = z$stats[, i], out =
## z$out[z$group == : Une valeur extrême (Inf) dans la boite de dispersion 2 n'est
## pas représentée
Nous allons faire les cartogrammes des teneurs en c_anne par couche de profondeurs. Pour cela, nous allons utiliser le fond de carte de la partie I.2.2.
# Nous rapatrions les coordonnées XY sur les résultats des splines
C <- c_anne_spline$harmonised
C <- left_join(C, poi, by=c("id"="id_profil"))
# supression des points sans coordonnées
C <-C %>% filter(!is.na(x_l93))
C <-C %>% filter(!is.na(y_l93))
# Nous convertissons les données XY en fichier spatial
C <- st_as_sf(C, coords = c("x_l93", "y_l93"), crs = st_crs(mayenne))
# Pour ne conserver que les points de la zone d'étude
C <- st_join(C, mayenne, left = FALSE)
plot13 <- ggplot() +
geom_sf(data = mayenne) +
geom_sf(data = C, aes(color = `0-5 cm`))+
scale_color_viridis_c(option = "H", limits=c(0, 100), na.value = "transparent") +
theme(legend.position = "right") +
labs(title = "C Anne 0-5 cm", fill = "c_anne") +
labs(color="g/kg") +
theme(legend.title = element_text(color="black", size=10, face = "bold"))+
theme_void()+
annotation_scale(location = "bl", line_width = 0.5, style="ticks", width_hint = 0.1, text_face=1,
pad_x = unit(0, "in"), pad_y = unit(0, "in"),) + # ajout d'une échelle
annotation_north_arrow(location = "br", which_north = "true", # ajout d'une flèche Nord
pad_x = unit(-0.09, "in"), pad_y = unit(0.1, "in"),
style = ggspatial::north_arrow_nautical(
fill = c("grey40", "white"),
line_col = "grey20",
text_family = "ArcherPro Book"))
plot14 <- ggplot() +
geom_sf(data = mayenne) +
geom_sf(data = C, aes(color = `5-15 cm`))+
scale_color_viridis_c(option = "H", limits=c(0, 100), na.value = "transparent") +
theme(legend.position = "right") +
labs(title = "C Anne 5-15 cm", fill = "c_anne eau") +
labs(color="g/kg") +
theme(legend.title = element_text(color="black", size=10, face = "bold"))+
theme_void()+
annotation_scale(location = "bl", line_width = 0.5, style="ticks", width_hint = 0.1, text_face=1,
pad_x = unit(0, "in"), pad_y = unit(0, "in"),) + # ajout d'une échelle
annotation_north_arrow(location = "br", which_north = "true", # ajout d'une flèche Nord
pad_x = unit(-0.09, "in"), pad_y = unit(0.1, "in"),
style = ggspatial::north_arrow_nautical(
fill = c("grey40", "white"),
line_col = "grey20",
text_family = "ArcherPro Book"))
plot15 <- ggplot() +
geom_sf(data = mayenne) +
geom_sf(data = C, aes(color = `15-30 cm`))+
scale_color_viridis_c(option = "H", limits=c(0, 100), na.value = "transparent") +
theme(legend.position = "right") +
labs(title = "C Anne 15-30 cm", fill = "c_anne eau") +
labs(color="g/kg") +
theme(legend.title = element_text(color="black", size=10, face = "bold"))+
theme_void()+
annotation_scale(location = "bl", line_width = 0.5, style="ticks", width_hint = 0.1, text_face=1,
pad_x = unit(0, "in"), pad_y = unit(0, "in"),) + # ajout d'une échelle
annotation_north_arrow(location = "br", which_north = "true", # ajout d'une flèche Nord
pad_x = unit(-0.09, "in"), pad_y = unit(0.1, "in"),
style = ggspatial::north_arrow_nautical(
fill = c("grey40", "white"),
line_col = "grey20",
text_family = "ArcherPro Book"))
plot16 <- ggplot() +
geom_sf(data = mayenne) +
geom_sf(data = C, aes(color = `30-60 cm`))+
scale_color_viridis_c(option = "H", limits=c(0, 100), na.value = "transparent") +
theme(legend.position = "right") +
labs(title = "C Anne 30-60 cm", fill = "c_anne eau") +
labs(color="g/kg") +
theme(legend.title = element_text(color="black", size=10, face = "bold"))+
theme_void()+
annotation_scale(location = "bl", line_width = 0.5, style="ticks", width_hint = 0.1, text_face=1,
pad_x = unit(0, "in"), pad_y = unit(0, "in"),) + # ajout d'une échelle
annotation_north_arrow(location = "br", which_north = "true", # ajout d'une flèche Nord
pad_x = unit(-0.09, "in"), pad_y = unit(0.1, "in"),
style = ggspatial::north_arrow_nautical(
fill = c("grey40", "white"),
line_col = "grey20",
text_family = "ArcherPro Book"))
plot17 <- ggplot() +
geom_sf(data = mayenne) +
geom_sf(data = C, aes(color = `60-100 cm`))+
scale_color_viridis_c(option = "H", limits=c(0, 100), na.value = "transparent") +
theme(legend.position = "right") +
labs(title = "C Anne 60-100 cm", fill = "c_anne eau") +
labs(color="g/kg") +
theme(legend.title = element_text(color="black", size=10, face = "bold"))+
theme_void()+
annotation_scale(location = "bl", line_width = 0.5, style="ticks", width_hint = 0.1, text_face=1,
pad_x = unit(0, "in"), pad_y = unit(0, "in"),) + # ajout d'une échelle
annotation_north_arrow(location = "br", which_north = "true", # ajout d'une flèche Nord
pad_x = unit(-0.09, "in"), pad_y = unit(0.1, "in"),
style = ggspatial::north_arrow_nautical(
fill = c("grey40", "white"),
line_col = "grey20",
text_family = "ArcherPro Book"))
plot18 <-ggplot() +
geom_sf(data = mayenne) +
geom_sf(data = C, aes(color = `100-200 cm`))+
scale_color_viridis_c(option = "H", limits=c(0, 100), na.value = "transparent") +
theme(legend.position = "right") +
labs(title = "C Anne 100-200 cm", fill = "c_anne eau") +
labs(color="g/kg") +
theme(legend.title = element_text(color="black", size=10, face = "bold"))+
theme_void()+
annotation_scale(location = "bl", line_width = 0.5, style="ticks", width_hint = 0.1, text_face=1,
pad_x = unit(0, "in"), pad_y = unit(0, "in"),) + # ajout d'une échelle
annotation_north_arrow(location = "br", which_north = "true", # ajout d'une flèche Nord
pad_x = unit(-0.09, "in"), pad_y = unit(0.1, "in"),
style = ggspatial::north_arrow_nautical(
fill = c("grey40", "white"),
line_col = "grey20",
text_family = "ArcherPro Book"))
plot_grid(plot13, plot14, plot15, plot16, plot17, plot18)## Ignoring unknown labels:
## • fill : "c_anne"
## Ignoring unknown labels:
## • fill : "c_anne eau"
## Ignoring unknown labels:
## • fill : "c_anne eau"
## Ignoring unknown labels:
## • fill : "c_anne eau"
## Ignoring unknown labels:
## • fill : "c_anne eau"
## Ignoring unknown labels:
## • fill : "c_anne eau"